
原paper:https://ieeexplore.ieee.org/document/8594844
源码解读:https://github.com/Guadzilla/Paper_notebook/tree/main/SASRec
中译:自注意序列推荐
总结:比较早使用self-attention的序列推荐模型
Abstract
- question作者想解决什么问题?
序列动态是许多当代推荐系统的一个重要特征,它试图根据用户最近执行的操作来捕捉用户活动的“上下文“。RNN模型可以在稠密数据集上捕捉长期语义。(马尔科夫链)MC模型可以在稀疏数据集上仅根据最近几次action做出预测。本文想平衡这两个目标:在稀疏和稠密数据集上做到捕捉长期语义、依赖较少的action做预测。
- method作者通过什么理论/模型来解决这个问题?
本文提出了一个基于self-attention的序列模型(SASRec),在每个时间步寻找与用户历史最相关的物品作为next item的预测。
- answer作者给出的答案是什么?
在稀疏和稠密数据集上,与MC/CNN/RNN方法相比都取得了SOTA效果。
Introduction
- why作者为什么研究这个课题?
MC方法模型简单,但因为它的强假设(当前预测仅取决于最近n次)使得它在稀疏数据上表现好,但是不能捕捉更复杂的动态转换。RNN方法需要稠密数据,并且计算复杂。最近出现新的序列模型Transformer,它是基于self-attention的,效率高并且可以捕获句子中单词的句法和语义模式。受self-attention方法启发,应用到序列推荐上。
- how当前研究到了哪一阶段?
第一个将transformer里的self-attention应用到了序列推荐上。
- what作者基于什么样的假设(看不懂最后去查)?
Conclusion
- 优点
- SASRec模型建模了整个序列,自适应地考虑items来预测
- 在dense和sparse的数据集上效果都很好
- 比CNN/RNN方法快了一个数量级
- 缺点
- 展望
- 引进更多上下文信息,比如等待时间、行为类型、位置、设备等。
- 探索处理超长序列(如clicks)的方法
Dataset & Metric
- 数据来源 (都开源)
- Amazon
- Steam 作者爬的,开源了
- Movielens
- 重要指标
- Hit@10
- NDCG@10
Method
这部分主要参考了知乎[1]](https://zhuanlan.zhihu.com/p/277660092?utm_source=qq))

1.Embedding层

A. Positional Embedding
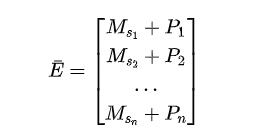
2.Self-Attention Block
A.Self-Attention Layer

C.Point-Wise Feed-Forward Network: 尽管self-attention能将之前item的emebdding使用自适应的权重进行集成,但仍然是一个先线性模型,为了加入非线性能力, 我们使用两层的DDN,

3.Stacking Self-Attention Blocks
在第一个self-attention block之后,学习item的迁移可以学习更加复杂的item迁移,所以我们对self-attention block进行stacking,第b(b>1)的block可以用下面的形式进行定义:

4.Prediction Layer

使用同质(homogeneous)商品embedding的一个潜在问题是,它们的内部产品不能代表不对称的商品转换。然而,我们的模型没有这个问题,因为它学习了一个非线性变换。例如,前馈网络可以很容易地实现同项嵌入的不对称性,经验上使用共享的商品embedding也可以大大提升模型的效果;
显示的用户建模:为了提供个性化的推荐,现有的方法常用两种方法,(1).学习显示的用户embedding表示用户的喜好;(2).考虑之前的行为并且引入隐式的用户embedding。此处使用并没有带来提升。
5.网络训练

6.方案复杂度分析
a. 空间复杂度
模型中学习的参数来自于self-attention.ffn以及layer normalization的参数,总的参数为:
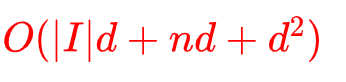
b. 时间复杂度
我们模型的计算复杂度主要在于self-attention layer和FFN网络,
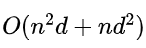
里面最耗时间的还是self-attention layer, 不过这个可以进行并行化。
Experiment & Table
该次实验主要为了验证下面的四个问题:
- 是否SASRec比现有最好的模型(CNN/RNN)要好?
- 在SASRec框架中不同的成份的影响怎么样?
- SASRec的训练效率和可扩展性怎么样?
- attention的权重是否可以学习得到关于位置和商品属性的有意义的模式?
1. 推荐效果比较
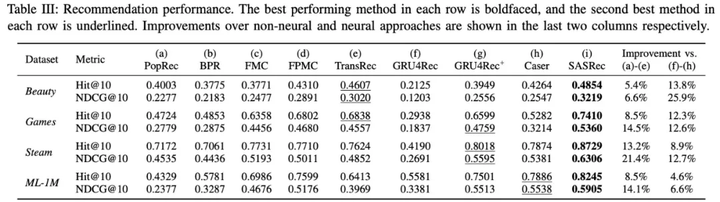
- SASRec在稀疏的和dense的数据集合熵比所有的baseline都要好, 获得了6.9%的Hit Rate提升以及9.6%的NDCG提升;
2. SASRec框架中不同成份的影响
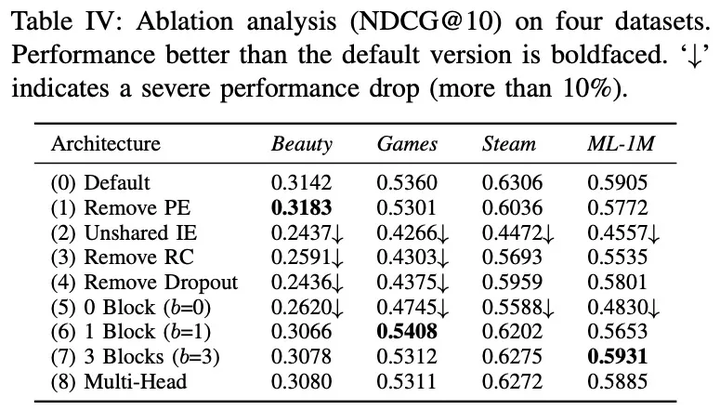
- 删除PE: 删除位置embedding ,在稀疏的数据集上,删除PE效果变好,但是在稠密的数据集上,删除PE的效果变差了。
- 不共享IE(Item Embedding): 使用共享的item embedding比不使用要好很多;
- 删除RC(Residual Connection):不实用残差连接,性能会变差非常多;
- 删除Dropout: dropout可以帮助模型,尤其是在稀疏的数据集上,Dropout的作用更加明显;
- blocks的个数:没有block的时候,效果最差,在dense数据集上,相比稀疏数据多一些block的效果好一些;
- Multi-head:在我们数据集上,single-head效果最好.
3. SASRec的训练效率和可扩展性
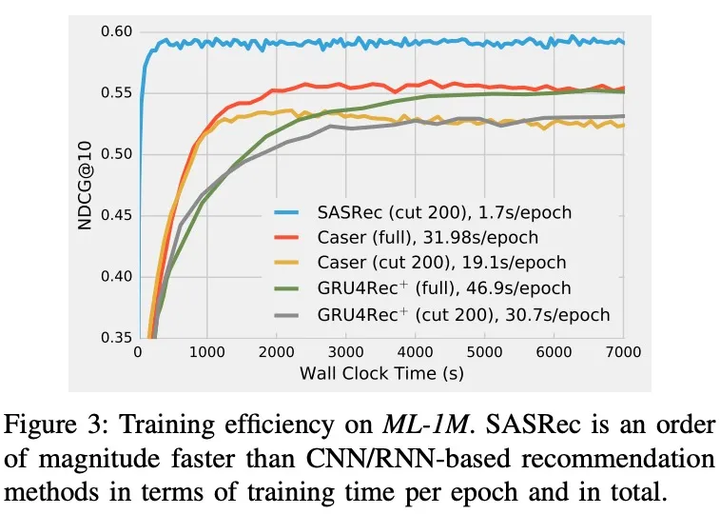
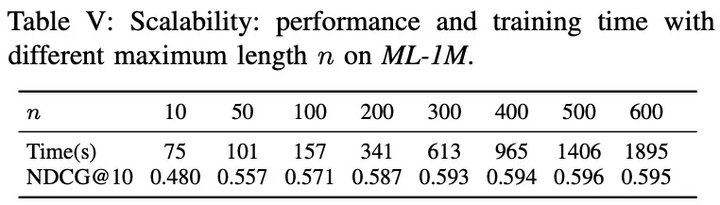
- SASRec是最快的;
- 序列长度可以扩展至500左右.