
源码解读:未开源
中译:流会话推荐
总结:第一篇结合了流推荐和会话推荐的论文(准备开坑)。主要解决两个问题,MF attention + GRU 解决用户行为的不确定性;存储技术+主动采样策略 解决了更贴近实时场景的“高速、海量、连续的流数据”的需求。个人认为可以进一步做的地方:session encoder部分,用新模型;储存技术;采样技术。
Abstract
question作者想解决什么问题?
1)用户行为的不确定性。
2)会话推荐在实际场景中会以会话流的形式出现,即连续不断的、海量的、高速的会话数据,但现有会话推荐模型都是离线模型,没有模型可以解决这个问题。
method作者通过什么理论/模型来解决这个问题?
作者提出SSRM(Streaming Session-based Recommendation Machine)模型,其中
1)为了解决用户行为的不确定性,作者利用历史交互,提出基于矩阵分解的注意力模型。
2)为了解决流会话数据“海量”、“高速”的挑战,作者基于存储提出使用主动采样策略的流模型。
answer作者给出的答案是什么?
在LastFM和Gowalla数据集上证明了SOTA。
Introduction
第一篇提出流会话推荐模型的论文。
why作者为什么研究这个课题?
“流会话”(Streaming session)的设定更贴近实际。
how当前研究到了哪一阶段?
第一篇提出流会话推荐模型的论文。
what作者基于什么样的假设(看不懂最后去查)?
1)用户的历史交互信息是可获得的
2)背景是流会话的设定,即会话数据海量、连续不断、迅速地迭代。
Dataset & Metric
- 数据来源
LastFM:http://mtg.upf.edu/static/datasets/last.fm/lastfm-dataset-1K.tar.gz
Gowalla:https://snap.stanford.edu/data/loc-gowalla.html
- 数据划分
给数据集 $D$ 中的会话按时间排序,分成前60%作为训练集,和后40%作为候选集。为了模拟线上的流数据输入,将候选集再划分成5个等长切片作为测试机。第一个测试机和10%的训练集作为验证集。实验中,若要预测第 $i$ 个测试集的序列行为,那么 $i$ 之前的测试集切片都用作在线训练。
- 重要指标
MRR@20、Recall@20
Method

SSRM的主要工作是,建立一个基于注意力的会话推荐系统(离线模型),再将其拓展到流会话的设定。
离线模型 = 建模序列 + 矩阵分解
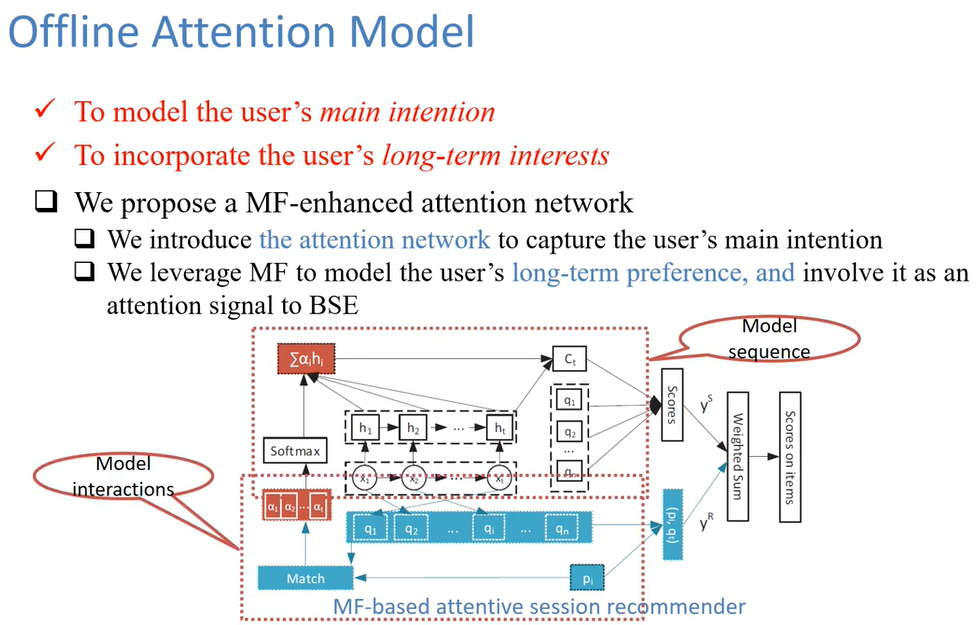
其中,建模“序列” = 基础会话编码器 + 基于矩阵分解的注意力会话编码器。这两部分如下1.2.:
- 基础会话编码器(Basic Session Encoder)
主要为了建模当前会话的表示。采用基本的GRU模型(重置门、更新门、候选状态),将最后一个隐藏状态作为当前会话 $i$ 的基本表示: $c_i = h_t$ 。
- 基于矩阵分解的注意力会话编码器(MF-based Attentive Session Encoder)
MF分解得到每个用户的隐含表示 $p_u \in \R ^ {1 \times D} $ 和每个物品的隐含表示 $q_t \in \R ^ {1 \times D} $ 。MF既用来单独作为一个模块,还通过引入MF(利用了历史交互信息)来加强上面的基础模型。
$p_u $ 和 $q_t$ 的内积 $\hat y_{u,t}^R =
为了降低随机性、捕捉用户 $u$ 的主要意图,这里使用了注意力机制编码会话表示 $c_i$:
其中权重 $\alpha_u = softmax(\hat y_u^R)$ ,即对用户 $u$ 对序列中物品的“喜欢”程度的打分进行softmax,得到和为1的权重。求到加权的表示后,再与GRU得到的会话表示 $h_t$ 拼接,作为最终的会话表示(这里 $h_t$ 用到了两次,一次作为最后一个物品表示,一次作为会话表示)。
- 混合注意力推荐系统
SSRM再进一步将注意力编码器的输出和MF的输出结合,使得模型不仅考虑当前会话的序列行为,还考虑了用户的长期兴趣和共现行为。
会话编码器最后输出,每个会话对每个物品的打分: $\hat y_{i,t}^S = q_t B c_i^T $ ,表示第 $i$ 个会话对物品 $t$ 的i打分,其中 $q_t \in \R ^ {1 \times D} $ , $c_i \in \R ^ {1 \times H} $ ,变换矩阵 $B \in \R ^ {D \times H} $ 。
由MF得到的 $p_u$ 和 $q_t$ 的内积 $\hat y_{u,t}^R =p_u \cdot q_t$ 。
两者使用一个可调参数 $w$ 加权求和 $\hat y_{i,t} = w \hat y_{i,t}^R + (1-w)\hat y_{i,t}^S $ 。
最后,把物品排序任务当作分类任务,使用CE loss损失函数训练模型。 $r_u$ 是物品的真实标签分布, $\hat y_u$ 是预测的概率分布。
建立完基于注意力的会话推荐系统(离线模型)后,再将其拓展到流会话的设定。建立存储的目的是准确地概括总结历史行为。
1.传统模型的更新方法
随机采样技术。令 $C$ 为保存会话序列的存储库,令 $t$ 为下一个时刻即将到达的数据实例。当 $t>|C|$ 时,存储库会以 $\frac{|C|}{t} $ 的概率存储这个数据实例,同时随机替换掉存储库 $C$ 里的数据实例。这样得到的存储库可以证明相当于当前数据集的随机采样结果,同时也证明可以保留模型的长期记忆[1]。但是 $\frac{|C|}{t} $ 是随时间递减的,这样模型就会倾向于忽略最近的数据,因为越近的数据被选入存储库的概率越低。而实际场景中是存在用户兴趣漂移的现象的,换句话说,使用这种随机采样技术难以实现“捕捉最新产生的数据中的行为模式”。
2.主动采样策略
虽然更新时同时使用整个存储库和所有新到达数据能产生更好结果,但是由于高速的流数据和有限的计算资源,这种方式通常会导致可利用的数据非常少(这个问题也被称为系统过载)。所以需要一个明智的样本选择策略。
本文提出的主动采样策略的思想和一些主动学习(Active learning)类似,即“选择对系统贡献最大的样本的最小集合”,供用户评估。具体来说,为了使模型在有限时间窗口内尽可能地多学习,采样策略每次应该选择 $C^{new}\cup C$ 中信息量最大的会话实例。
计算会话的信息量,使用会话中每个物品得分的均值,其中物品得分 $r_{u,k}$ 表示用户 $u$ 在当前模型下对物品 $k$ 的预测能力,使用用户隐含表示和物品隐含表示做内积得到 $r_{u,k}=p_u q_k$。$r_{u,k}$ 值越小, $r_{s_i}$ 值越小,说明模型越难以预测该会话中的物品,说明该会话信息量越大,越能修正模型,越该对它进行采样。
以 $r_{s_i}$ 值对这些会话降序排列,再根据排名计算每个会话的权重因子 $w_{s_i}$,最后得到每个会话的采样概率 $p(s_i)$ :
其中,信息量越大的会话排名越靠后,权重因子越高,采样概率也越大。
Experiment & Table

SOTA。LastFM的提升率比Gowalla高的主要原因是,Gowalla更系数,每个用户的点击很少,并且会话数据只有寥寥几个,从而导致训练不充分。
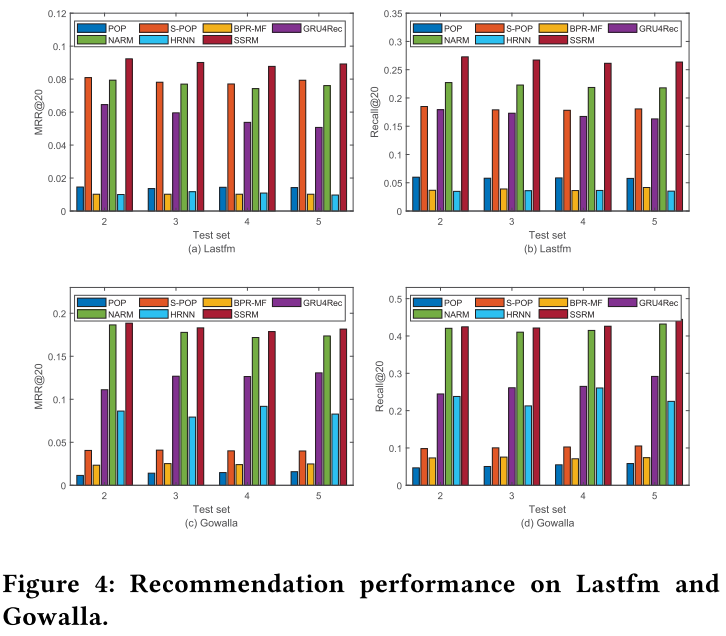
Baseline:只有基础会话编码器(Basic session encoder),好像就是GRU4Rec。三个模型采用相同的streaming技术,以消除线上更新方法带来的影响。SSRM效果最好。

S1:没有存储库,且仅用新来的数据更新模型。S2:有存储库,采用从 $C$ 中随机采样训练的传统方法。S3:S2的基础上,从 $C\cup C^{new}$ 中采样。S1、S3优于S2,说明相比于历史long-term memory,模型更能从用户最近行为中受益。而SSRM模型优于其它所有,说明本文提出的主动采样策略是有效的。

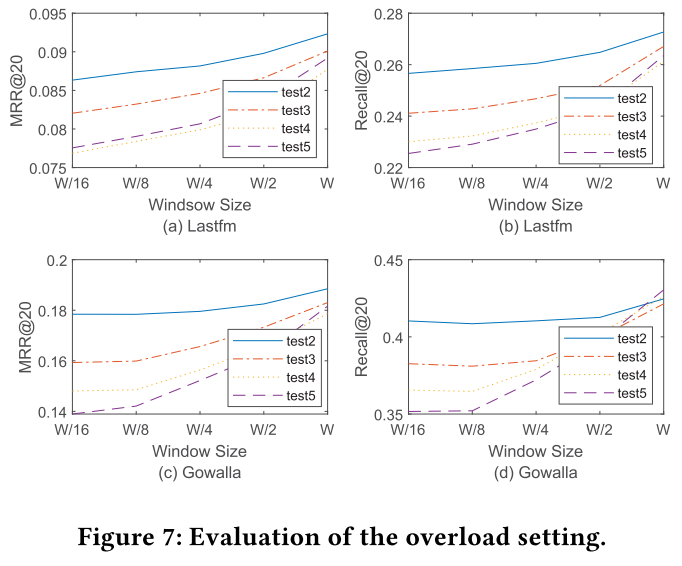
$W$ :固定时间窗口,即一次能从 $C\cup C^{new}$ 中采样的样本数。 $W$ 越小说明工作负载越重,只训练到有限的序列。横轴看,窗口越大,过载越轻,模型表现越好;反之窗口越大,过载越重,模型表现越差。纵向看不同测试集,因为这些测试集是按时间顺序分的,越往后新用户、新物品越多。但是可以发现,从test2到test5,它们之间的gap越来越小。SSRM能够快速减小这种gap,证明其处理新数据的能力。
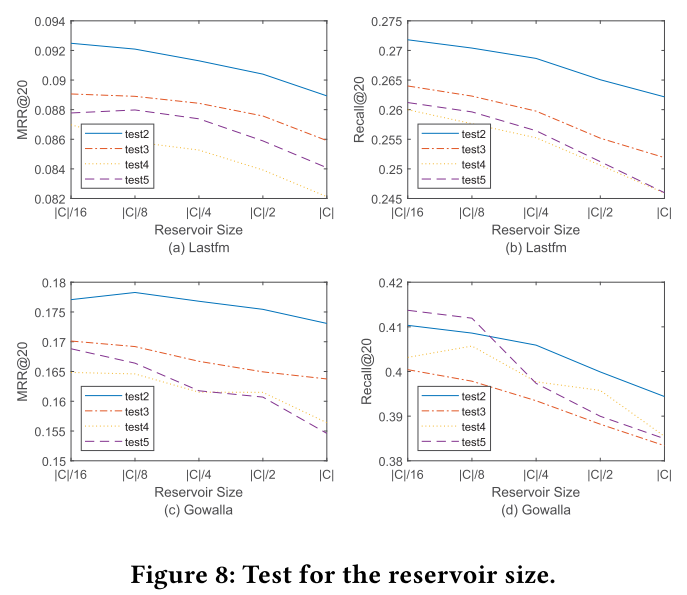
存储库大小的影响
$|C|$ 的大小决定了保留多少历史信息,它保留的观测行为越多,就越可能从历史行为中采样,就会有更多的样本距离current behavior越久远,故模型就会用更少的当前会话信息来更新。换句话说,对于过去没有出现的用户和项目,模型会学习得更少,这将导致性能相对较差。Figure 6 里也能得出这个结论,最近的行为更重要。但是因为存在long-memory problem,如果只用当前session来训练模型的话,结果会变低,总的来说,历史行为和当前行为两者得结合起来。
参考资料
[1]Ernesto Diaz-Aviles, Lucas Drumond, Lars Schmidt-Thieme, and Wolfgang Nejdl. 2012. Real-time top-n recommendation in social streams. RecSys (2012)