RecBole是个非常好的开源库,这几天做评测的时候用上了,奈何本人能力有限,遇到了非常多bug(可能是自己行为造成的),简单记录一下。可以参考这个:RecBole小白入门系列_Turinger_2000的博客-CSDN博客
使用方法就是:RUCAIBox/RecBole (github.com),下载下来unzip或者clone到设备上。然后再RecBole主目录下编写一个test.yaml文件记录一些配置,再运行run_recbole.py就可以。test.yaml大概要设置4类东西:dateset setting, model setting, train setting, evaluate setting.
整个项目文件如下,几个比较重要的文件夹和文件标出来了,后面会说到。
接下来以一个用自己数据集跑SASRec模型的例子说明如何使用RecBole。
配置test.yaml文件
构造数据集——data setting
如果想跑自己的实验,那么很重要的一件事就是构造自己的数据集,recbole要求个人首先构建可以处理的原子文件,然后就可以传给模型处理了。详细见:数据流 | 伯乐 (recbole.io)
根据原子文件 | 伯乐 (recbole.io),Sequential模型只需要.inter的原子文件,如下图:

虽然不知道.inter 是什么文件,但是可以看以下模型本身给的数据集以及处理好的原子文件模仿着构造。数据集保存在RecBole/dataset/ml-100k下(以ml-100k数据集为例),找到ml-100k.inter,用记事本打开格式如下:

BPR和CF等general model可能会用到rating(用户评分),timestamp。但是Sequential model一般只需要timestamp把点击行为构成对应用户的序列就行,想跑的SASRec论文附的代码里,对数据集的处理是:只保留user_id和item_id两列,按点击顺序存储。我的数据集book长这个样子:

只有两列特征user_id和item_id,看起来好像很接近,但是踩坑穿越回来的我可以告诉你,这里必须得有timestamp一列,recbole就是这么处理sequential model的数据集的,没有办法。那添加什么样的timestamp呢?book数据集是按点击顺序存储的(user_id已经重新从0开始标号),所以其实只要加个递增的timestamp就行了,这里用pandas简单处理下多加一列就行。

注意,这里用pandas处理的时候,顺便把列名改了。user_id和item_id后面加上”:token”,timestamp后面加上”:float”。RecBole要求这么做,后面也会说到。这样处理好文件后,pandas输出的一般是csv,重命名的时候要改成.inter后缀。然后在dataset下新建一个文件夹,起名为你的dataset名称xxx(可以自己起,这个很重要),然后.inter文件也要命名为xxx.inter,如图所示:

然后我们在RecBole主目录下新建一个test.yaml文件,在里面输入:(暂时不明白没事,抄下来就行)
1 | # dataset config |
需要注意前两条separator,csv文件的话默认分隔符是”,”,还有最后一行local:这里按照数据集的列指定就行,到此数据集基本构造好了。
用Sequential model类跑模型——model setting
以SASRec为例,想跑一个模型,如何看这个模型需要的参数?到 RecBole/recbole/properties/model 底下找到对应模型的yaml文件,打开以后大概长这样。
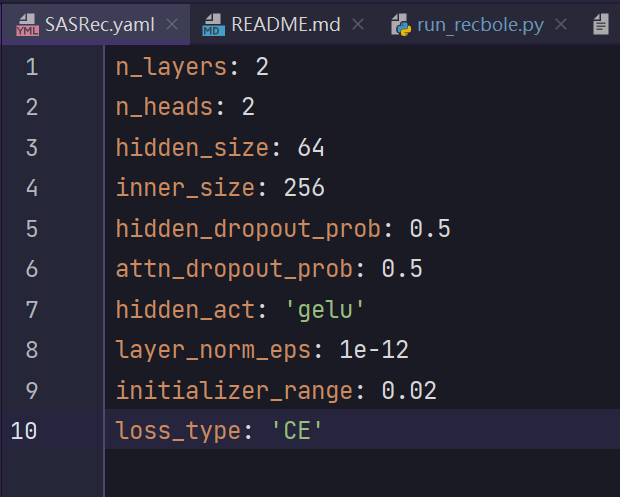
这里包含了模型需要的参数,每次调用都到这里改很麻烦,所以recbole可以实现用test.yaml的设置覆盖具体模型的设置,所以只要在test.yaml(主目录下的那个配置文件)里改我们添加,并做一点修改:
1 | n_layers: 2 |
训练设置——train setting
通用的训练设置也要写到test.yaml中:
1 | # training settings |
评估设置——evaluate setting
通用的评估设置也要写道test.yaml中:
1 | # evalution settings |
recbole实现了earlystopping早停策略,可以设置控制收敛的步骤数。
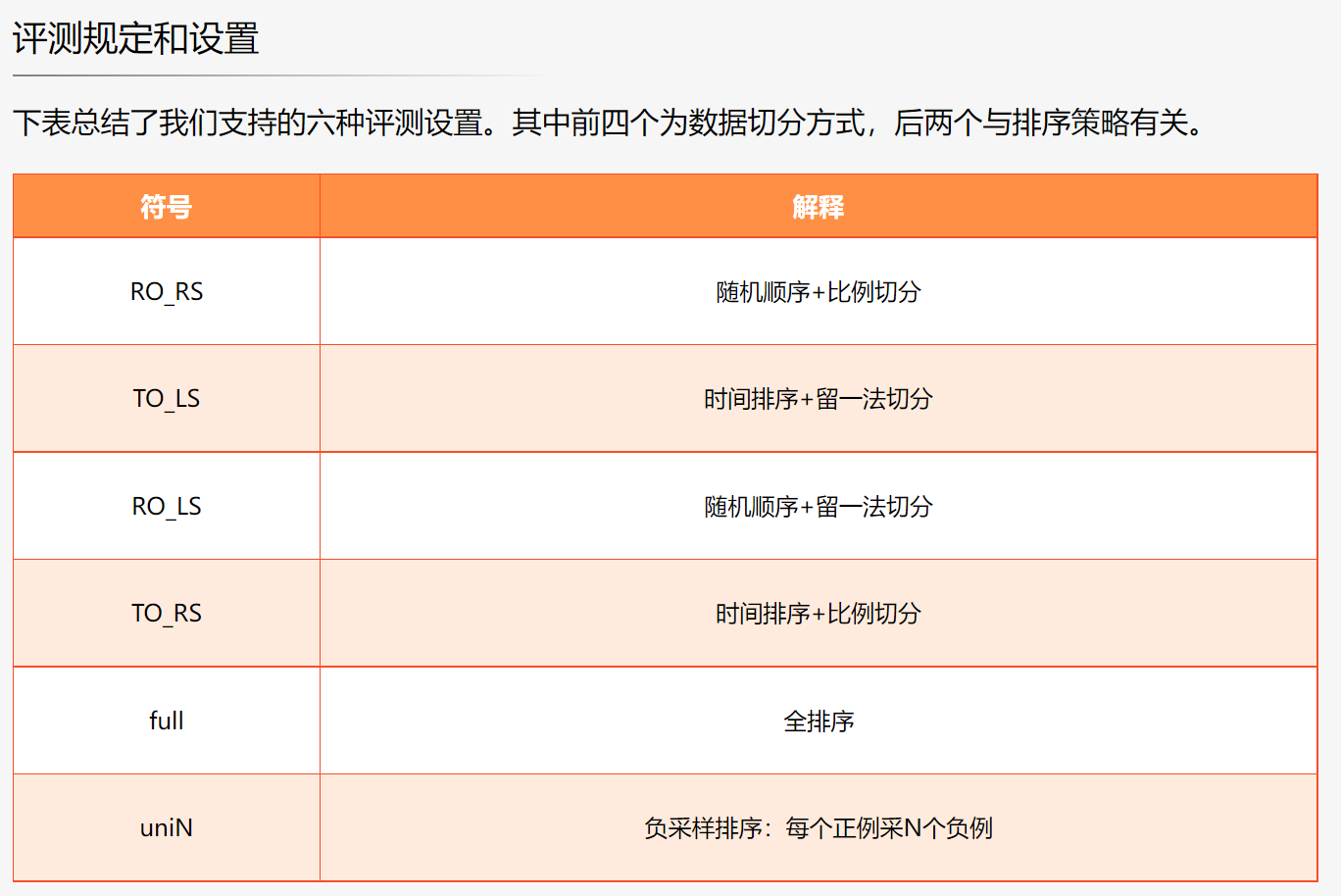
eval_setting,可以设置不同的数据切分方式,具体可见评测 | 伯乐 (recbole.io),大致如下:
run!跑起来吧,baseline!
我们cd到RecBole目录下,此时数据集已经准备好,test.yaml文件也已经写好,可以开始跑实验了,用以下指令:
1 | python run_recbole.py --model=SASRec --dataset=book ----config_files=test.yaml |
如果看不懂参数的话,点进run_recbole.py看一下就明白了!
总结
RecBole是个集成度很高,也比较方便用于复现一些基本推荐模型的开源库(在此致敬中国人民大学AI BOX小组!),需要用recbole跑自己的baseline时,只需要三步:
- 构造满足原子文件的数据集
- 写好.yaml格式的配置文件
- run!
记录一些遇到的坑
1. neg_sampling 不能使用 ‘CE’ loss
在配置文件中加上一行:
1 | neg_sampling: (注意这里冒号后面有个空格) |
2.使用不上gpu
问题描述:程序可以跑起来,但是nvtop看不到它在gpu上运行。并且无论如何修改配置文件都没有用。非常奇怪的问题。检查torch.cuda.is_available()的时候发现,居然输出False,所以原因是用不了CUDA。
问题原因:用不了CUDA。
用conda list检查安装的库时发现,默认安装的torch是cpu的

左边是默认安装的,想了一宿也没想明白为什么默认安装cpu版本
卸载cpu版本再安装cuda版本有点麻烦,所以我直接新建了一个环境,并且自带torch=1.10,然后再根据依赖安装,使用命令:
1 | pip install -r requirement.txt |
这里不用担心torch会被覆盖,因为torch版本大于1.17就会自动跳过了。
然后总可以跑了吧,运行下面指令(用RecBole需要这样输)
1 | python run_recbole.py --model=BERT4Rec --dataset=book ----config_files=bert4rec.yaml |
按理说此时torch是建环境时我安装的cuda版本,一定不是cpu版本,然而每次运行仍然是device=cpu。实在让人崩溃!
解决方案:
最后debug多轮,寻找到的解决方案是:
- 在run_recbole.py里import torch,并且打印torch.cuda.is_available()
这样做合理的可能的原因:
可能项目某个地方import torch,import进来的torch是cpu版本的,所以提前import可以解决。