任务6:Slope One
- 阅读Slope One基础原理
- 编写Slope One用于电影推荐的流程
- 比较Slope One、SVD、协同过滤的精度,哪一个模型的RMSE评分更低?
代码地址: https://github.com/Guadzilla/Basics-of-Recsys
slope one 算法
1.示例引入
我们可以这么认为,商品间受欢迎的差异从某种程度上是固定的,比如所有人都喜欢海底捞火锅,但对赛百味的喜爱程度一般。此时小明对海底捞火锅的评分为4,对赛百味的评分为2;而小吴对海底捞火锅的评分为5,对赛百味的评分为3。尽管两个人评分的习惯上不同,小明平均打的分都高,但是对两个物品来说,他们之间的评分差值是不变的,即 $5-3=4-2$ 。

Slope one 的思路大抵如此,现在假设我们想预测 Alice 对物品 2 的评分,已有的是别的用户对物品 1 和对物品 2 的评分和 Alice 对物品 1 的评分。
从物品评分偏差的角度,我们可以求出物品 1 和物品 2 之间的评分偏差,即 $R_{1,2}=\frac{(3-1)+(4-3)+(3-3)+(1-5)}{4}=-0.25$,再用 Alice 对物品 1 的评分减去这个偏差,即 $p_{Alice,2}=r_{Alice,1}-R_{1,2}=5-(-0.25)=5.25$,把它作为 Alice 对物品 2 的预测评分。这就是Slope one 算法最简单的场景。
slope one 算法思想
Slope One 算法是由 Daniel Lemire 教授在 2005 年提出的一个 Item-Based 的协同过滤推荐算法。和其它类似算法相比, 它的最大优点在于算法很简单, 易于实现, 执行效率高, 同时推荐的准确性相对较高。
Slope One算法是基于不同物品之间的评分差的线性算法,预测用户对物品评分的个性化算法。主要分为三步:
Step1: 计算物品之间的评分差的均值,记为物品间的评分偏差(两物品同时被评分);

Step2:根据物品间的评分偏差和用户的历史评分,预测用户对未评分的物品的评分。
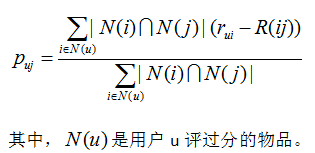
Step3:将预测评分排序,取topN对应的物品推荐给用户。
举例:
假设有100个人对物品A和物品B打分了,R(AB)表示这100个人对A和B打分的平均偏差;有1000个人对物品B和物品C打分了, R(CB)表示这1000个人对C和B打分的平均偏差;

slope one 的代码实现
1.准备数据
1 | # 定义数据集 |
2.建立倒排索引
1 | # 建立倒排索引 |
3.计算物品间评分偏差矩阵
1 | # 计算物品间评分偏差 |
4.预测评分
1 | # 预测评分 |
slope one使用场景
该算法适用于物品更新不频繁,数量相对较稳定并且物品数目明显小于用户数的场景。依赖用户的用户行为日志和物品偏好的相关内容。
优点:
1.算法简单,易于实现,执行效率高;
2.可以发现用户潜在的兴趣爱好;
缺点:
依赖用户行为,存在冷启动问题和稀疏性问题。
比较Slope One、SVD、协同过滤的精度,哪一个模型的RMSE评分更低?
| Model | RMSE |
|---|---|
| UserCF | 3.80369 |
| ItemCF | 3.74319 |
| SVD(MF) | 3.75332 |
| Slope One | 3.91533 |
参考资料:
https://blog.csdn.net/xidianliutingting/article/details/51916578