作者本人解读:https://mp.weixin.qq.com/s/kSayir_jVwZbhEPm0qtYPA
中译:基于用户价格偏好及兴趣偏好的会话推荐
总结:
异质超图=异质图+超图:异质图——融合异质特征,超图——捕捉高阶依赖
双通道聚合:intra + inter ,聚合同类和异类信息,获得价格和兴趣偏好的初级表示
协同指导学习:捕捉价格偏好和兴趣偏好之间的复杂联系,获得语义增强的价格和兴趣偏好的表示
Abstract
- question作者想解决什么问题?
现有会话推荐系统中关注如何建模用户的兴趣偏好,然而忽略了物品的一项重要属性,即价格。同时建模价格和兴趣偏好不是件容易的事情。首先,它很难处理来自物品的各种特征的异质信息来捕捉用户的价格偏好;其次,在决定用户选择时,很难对价格和兴趣偏好之间的复杂关系进行建模。
- method作者通过什么理论/模型来解决这个问题?
提出协同指导的异质超图网络(Co-guided Heterogeneous Hypergraph Network,CoHHN)。
对于第一个挑战,提出用异质超图来表示异质信息,接着通过双通道聚合机制聚合这些信息,再通过attention层提取用户的价格偏好和兴趣偏好。
对于第二个挑战,提出协同指导的学习方法,用来建模价格和兴趣偏好之间的关系。
- answer作者给出的答案是什么?
三个数据集中取得SOTA。
分析得出会话推荐任务中价格的重要性。
Introduction
- 动机
现有会话推荐系统中关注如何建模用户的兴趣偏好,然而忽略了物品的一项重要属性,即价格。但是许多市场研究展示出用户的购买行为非常容易受到价格因素的影响,所以价格应该被纳入考虑。
价格偏好的特点:动态,受商品类别影响。(例如用户可能为了性能而购买很贵的笔记本电脑,但是却买比较便宜的睡衣。)所以在纳入用户价格偏好时,我们需要考虑商品对应的类别。因此这种场景下,商品序列,商品价格,商品类别,这些异质信息会使得现有方法失效。
此外,经济学上有一种现象叫做价格弹性,即用户愿意为某一物品支付的金钱会随着用户对该物品的兴趣而波动。这一现象充分显示用户的购买行为是由价格和兴趣共同决定的。(例如越感兴趣的商品越愿意花高价钱买,愿意花低价买那些不是特别喜欢的商品)
针对上面两个挑战,分别提出解决方案。
- 现有的SOTA方法,只能捕捉 pairwise relation ,成对关系,例如商品序列、类别。本文提出的CoHHN中,异质超图结合了超图和异质图的优点。 超图可以捕捉比 pairwise 更高阶的依赖关系,具体是
- 提出 协同指导学习方法 ,用于建模价格和兴趣之间的复杂关系。具体来说,利用异质超图学到的原始价格和兴趣偏好,让他们互相指导对方的学习以增强语义信息。最后,基于商品特征、价格偏好、兴趣偏好,共同做出推荐。
- 基于什么样的假设?
价格偏好的特点:动态,受商品类别影响。
价格弹性现象。用户愿意支付的钱受兴趣影响,购买行为由兴趣和价格共同决定。
Preliminaries
- 会话推荐定义(略)

- 价格离散化:每个类别由不同的价格 level 。根据 logistic 分布(上图),使得划分的每一部分概率相同。
其中 $x_i$ 的价格 $x_p$ ,$x_i$ 所属类别的价格范围是 $[min,max]$ ,其中 $\Phi\left(x\right)$ 是概率分布函数。

异质超图构建:见上图,每个超边可以连接任意个节点,共有三种超边,特征超边,价格超边,会话超边。
- 1)特征超边连接一个 item 的所有特征:id、price、category;2)价格超边连接同一个会话中的价格节点;3)会话超边连接会话中所有的id节点。
- 特征超边用来在异质节点间传播信息,价格超边和会话超边用来提取用户的价格和兴趣偏好。
问题:为什么没有类别超边呢?因为类别信息用特征超边传播了,而且目的是获取价格和兴趣偏好?
- 问题:特征超边只用来传播不同特征?
Method
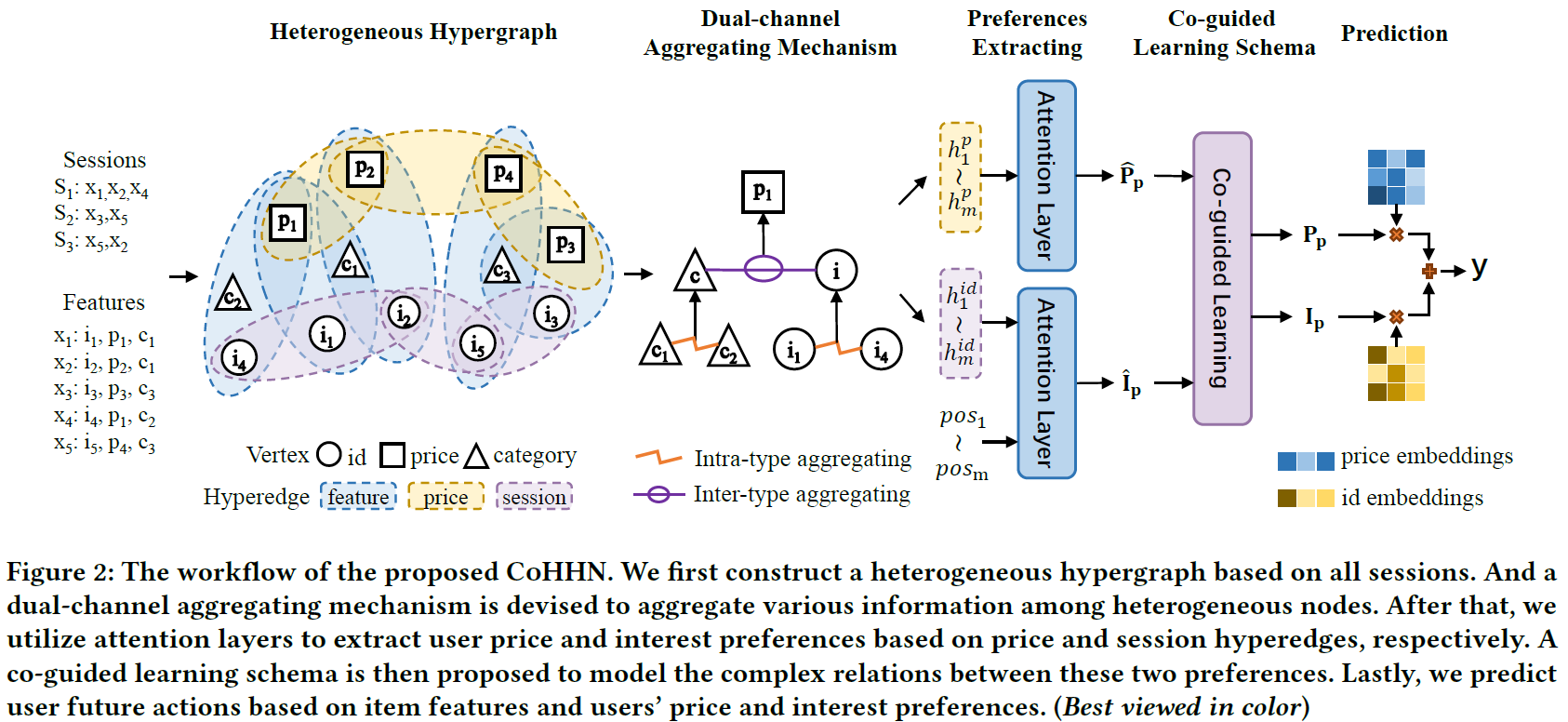
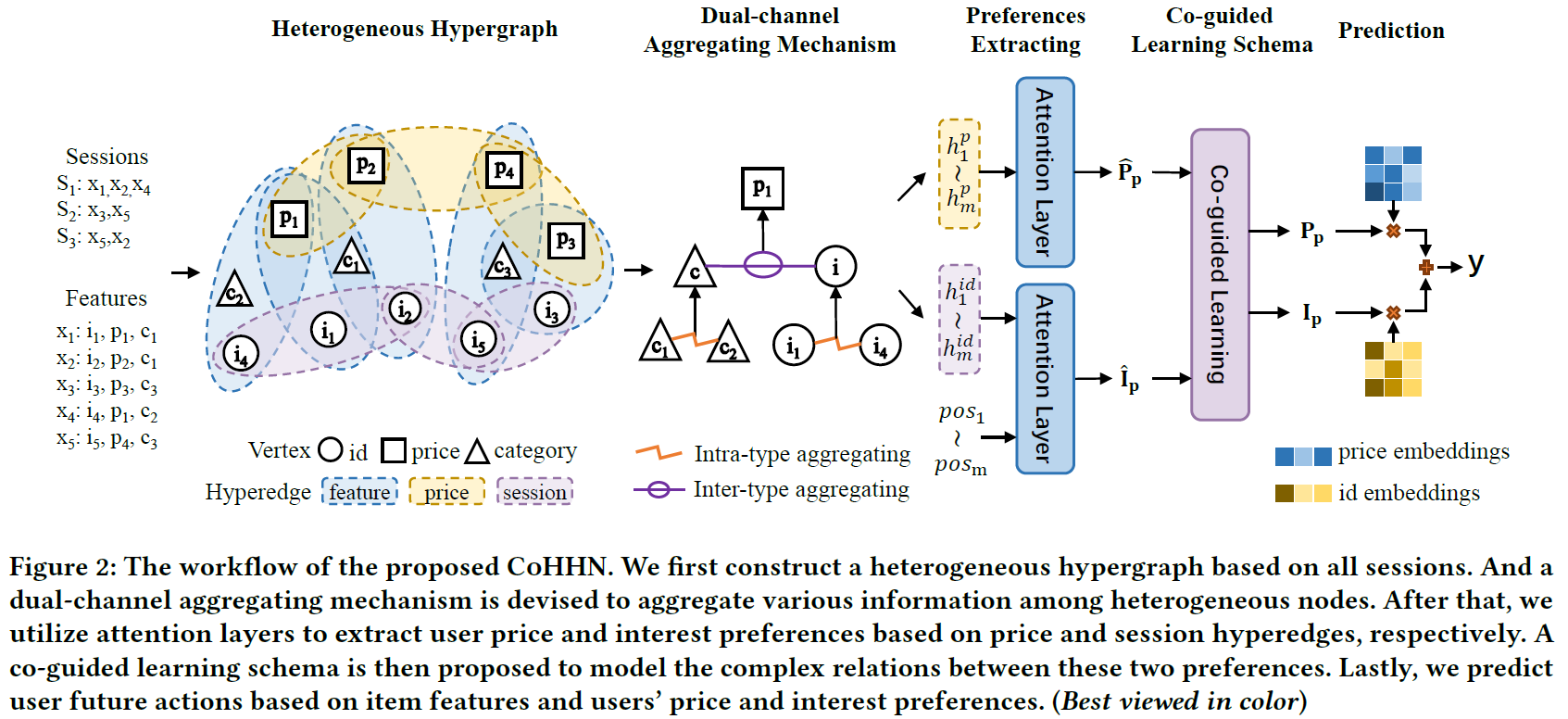
总览
首先基于所有会话数据构建异质超图,其次通过 Dual-channel 聚合 intra-type 信息和 inter-type 信息(注意不是 intra-session 和 inter-session);接着,通过 attention 层提取价格偏好和兴趣偏好,两种偏好经过协同指导学习增强语义,最后利用商品特征、价格偏好、兴趣偏好共同做出推荐。
双通道聚合机制
因为超边的存在,不同类别的节点会连接在一起。显然,拥有相同类型的节点提供同质的信息,不同类型的节点提供异质的信息,两种类型的节点对目标节点的贡献是不同类型的。所以设计两个通道, intro-type 通道和 inter-type 通道 。
Intra-type 聚合。 $v^t$ 是 target node 的 embedding,它的属于类别 $\tau$ 的邻接点集合为 $N^{\tau}_t$ 。同类聚合的目的是区分同类节点的重要性差异,并且聚合这些信息。公式如下:
其中 $u_{\tau}$ 是 attention vector,决定了类别 $\tau$ 的节点对目标节点的重要程度,这里不同类别有不同类别的 attention vector ,使得模型可以学到每个节点特定类别的 embedding 。 $e^{\tau}_t$ 是 target node $v^t$ 的类别 embedding 。 公式抽象为: $\mathbf{e}_{t}^{\tau}=f_{a}\left(N_{t}^{\tau}\right)$ 。
Inter-type 聚合。 基于学到的类别 embedding $e^{\tau}_t$ ,inter-type聚合的目的是聚合不同类别的 embedding 到目标节点上。公式如下:
其中 $W _ t,W ^ {\tau 1} _ t,W ^ {\tau 2} _ t$ 是可学习参数。 $h_t$ 是经过邻接的异质节点与以增强过的 target node 的 embedding 。 公式抽象为: $\mathbf{h}^{t}=f_{b}\left(\mathbf{v}^{t}, \mathbf{e}_{t}^{\tau 1}, \mathbf{e}_{t}^{\tau 2}\right)$ 。
双通道聚合公式如下:
上标代表类别,c:category,id:item id,p:price。可以看到每个类别的 embedding 都会融合另外两个类别的信息。
值得注意的是,邻接关系主要是基于特征超边的。
偏好提取
基于 $\mathbf{h}^{i d}、\mathbf{h}^{p}、\mathbf{h}^{c}$ 这三个节点 embedding ,进一步提取价格和兴趣偏好。
提取价格偏好。因为用户的价格偏好反映在他购买的商品,所以依据价格超边提取用户的价格偏好。用多头自注意力机制。没有加入时间信息是因为价格偏好相对稳定,并且表示集体性依赖而非序列性依赖。公式如下:
隐藏状态 $S_P$ 作为原始的价格偏好: $\hat{\mathbf{P}}_{p}=\mathrm{S}_{p}^{(t)}$ 。
提取兴趣偏好。依据会话超边提取用户兴趣偏好。因为兴趣可能随时间漂移,所以加入位置编码学习动态兴趣。这里使用 reversed position embedding,会话中第 $i$ 个物品的计算公式如下:
其中$\mathbf{W}_{f}$ 和 $\mathbf{b}_{f}$ 是可学习参数。再过 soft 注意力层:
其中 $\mathbf{A}_{1}、 \mathbf{A}_{2}、\mathbf{b}$ 是可学习参数,$\mathbf u^T$ 是 attention vector。$\overline{\mathbf{v}}^{*}$ 是 $\mathbf{v}_{i}$ 的均值,$\hat{\mathrm{I}}_{p}$ 是原始的兴趣偏好。
协同指导 Learning Schema
有了原始的兴趣偏好 $\hat{\mathrm{I}}_{p}$ 和原始的价格偏好 $S_P$ ,可以简单定义用户对物品 $x_i$ 的预测得分:
但是这种简单的加法方式不能处理复杂的情况,比如用户对越感兴趣的商品越愿意花高价钱买,同时愿意花低价买那些不是特别感兴趣的商品。所以提出协同指导的学习方法。
首先用两种方式融合 价格偏好 和 兴趣偏好 :
$\mathbf{m}_{c}$ 和 $\mathbf{m}_{j}$ 用来表示不同语义空间下的价格和兴趣间交互关系。接着用门控机制进一步建模价格偏好和兴趣偏好之间的相互关系(mutual relations)。
其中 $\mathbf W$ 和 $\mathbf U$ 是可学习参数,$\mathbf r$ 是记忆门。$\mathbf m$ 是语义增强后的价格和兴趣偏好表示。最终的价格和兴趣偏好表示如下:
这里再次增强语义。
预测和训练
预测得分:$y_{i}=\mathbf{P}_{p}^{\top} \mathbf{v}_{i}^{p}+\mathbf{I}_{p}^{\top} \mathbf{v}_{i}^{i d}$
转化为概率:$y_{i}=\frac{\exp \left(y_{i}\right)}{\sum_{j=1}^{n} \exp \left(y_{j}\right)}$
CE loss:$\mathcal{L}(\mathrm{p}, \mathrm{y})=-\sum_{j=1}^{n} p_{j} \log \left(y_{j}\right)+\left(1-p_{j}\right) \log \left(1-y_{j}\right)$ ,其中 $p_{j}$ 是真实标签。
Experiment Setup
研究问题
- RQ1:SOTA了吗?
- RQ2:价格因素的影响如何?
- RQ3:协同指导学习方法的影响如何?
- RQ4:不同价格 level 的影响如何?
- RQ5:关键超参数的影响如何?
数据集 和 预处理
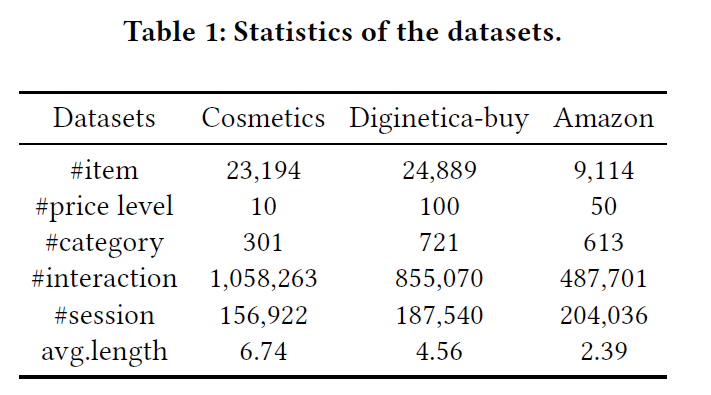
Cosmetics ,We use one month (October 2019) records and only retain the interactions with type “add_to_cart” or “purchase” in our work.
Amazon,Grocery and Gourmet Food.
预处理:过滤掉长度为1的会话,出现次数小于10的物品。序列最后一位作为label,前面的用来建模用户偏好。时间顺序,前70%作为训练集,后20%作为验证集,最后10%作为测试集。
评价指标
Precision、MRR,@10,@20.
结果分析
RQ1:SOTA了吗?
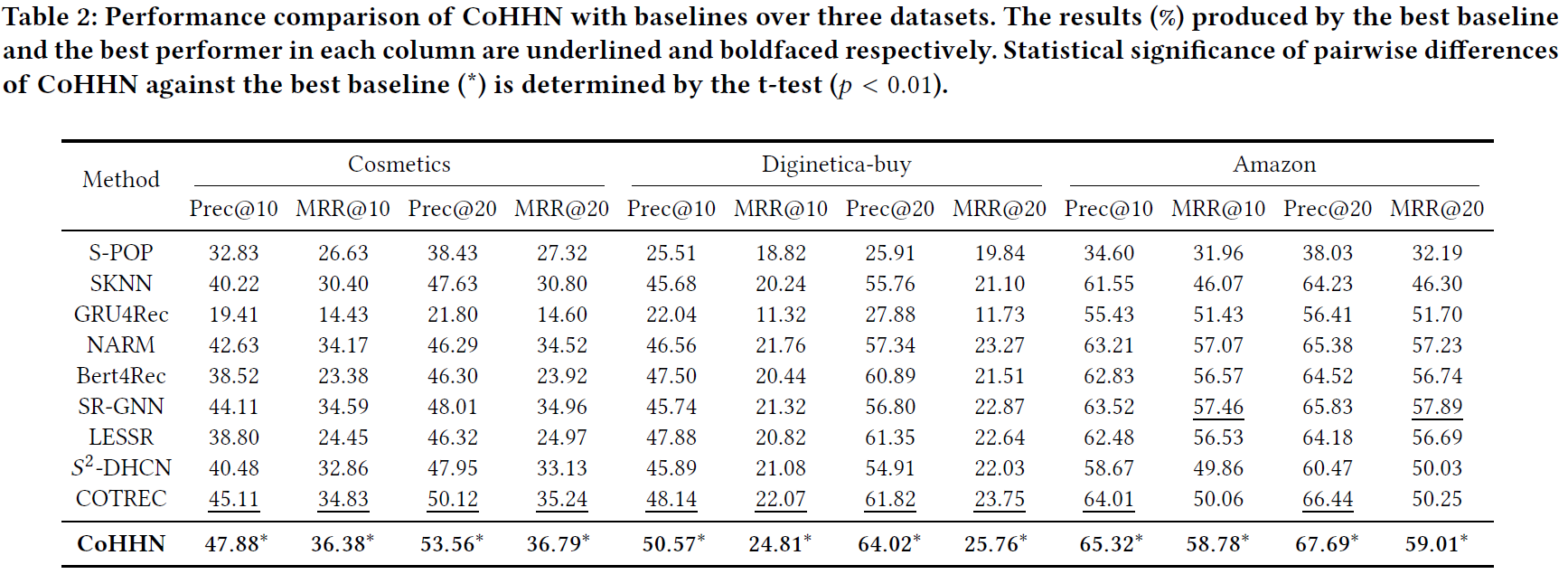
SOTA了。进一步分析:(1)NARM和Bert4Rec比GRU4Rec好的原因,注意力机制,但Bert4Rec效果没有达到预期的原因是,序列比较短;(2)SR-GNN、LESSR在图上建模 pairwise relation,$S^2-$DHCN和COTReec与之相比建模了比成对关系更高阶的关系,所以表现更好,但是也局限建模在单一类型交互上。CoHNN在此基础上用更多的特征建模了价格和兴趣偏好,效果更好。
RQ2:价格因素的影响如何?

价格特征和价格偏好的影响
CoHHN-c:去掉category特征,CoHHN-p:去掉价格特征(自然也没有协同指导学习?),CoHHN-pp:节点更新时考虑价格特征但没有提取价格偏好(自然也没有协同指导学习?)。
(1)CoHHN-pp > CoHHN-p、CoHHN-c > CoHHN-p :加入价格特征有用;
(2)CoHHN > CoHHN-pp :考虑价格偏好有用;
(3)CoHHN > CoHHN-c:考虑类别特征有用,可以更准确地学习价格偏好。
不同分布划分的影响
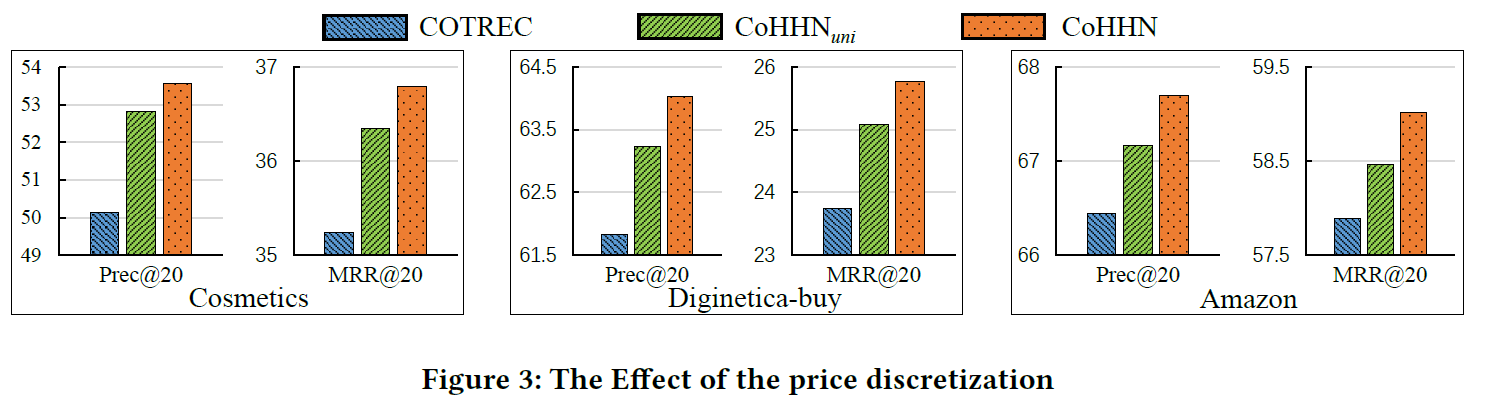
logistic 分布 > 均匀分布 ,logistic 分布能更准确反映价格信息。
均匀分布 > COTREC ,考虑价格因素,即使用均匀分布也高于之前的 SOTA ,说明考虑价格因素的有效性。
RQ3:协同指导学习方法的影响如何?
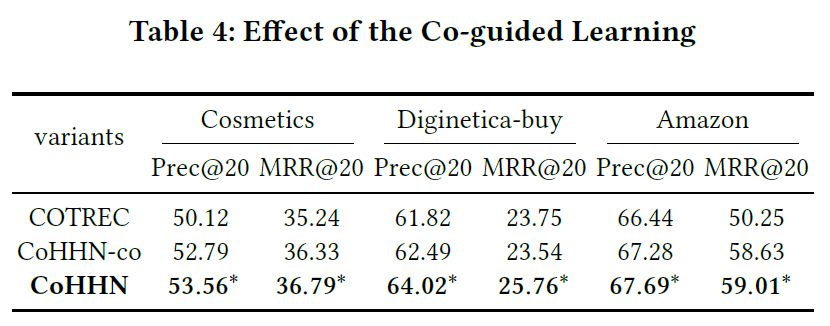
CoHHN-co:对价格偏好和兴趣偏好简单加和,没用协同指导学习方法。
CoHHN > CoHHN-co :证明价格偏好和兴趣偏好之间的关系复杂,简单加和无法提取。协同指导学习的方法可以。
RQ4:不同价格 level 的影响如何?
也就是每个类别的价格分的那几个桶,各自的表现如何。
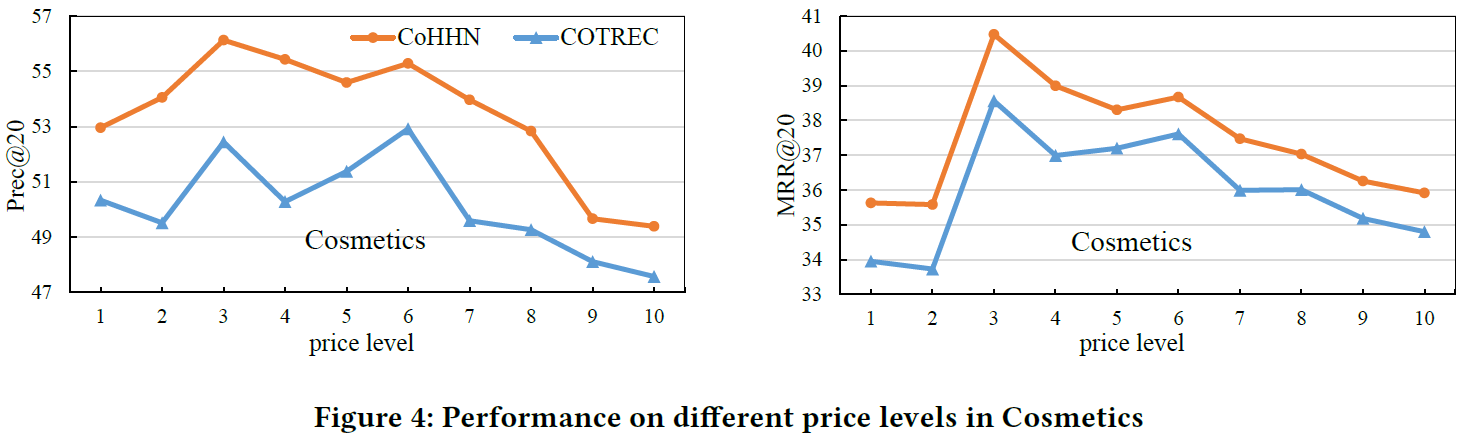
CoHHN在所有 level 都优于 COTREC,可能的原因是,离散化价格的方法可以优化价格分配。
其次,在中低价位,两个模型表现都比较好,这和大多数人的购物习惯一致,倾向于购买中低价位的商品。
RQ5:关键超参数的影响如何?
价格 level 的数量的影响
也就是每个类别,价格各分几个桶,决定了建模的价格粒度。

(1)越低粒度越粗,但是太高会使得价格相似的物品也区分开,就没有意义了。
(2)其次,不同数据集价格分布不同,也会导致最优效果的粒度不同。
(3)从绝对值来看,三个数据集接近最优 number of level 的附近,呈现出稳定的性能。本文认为,得益于所提出的离散化方法。
双通道聚合迭代次数
类似GNN层数。
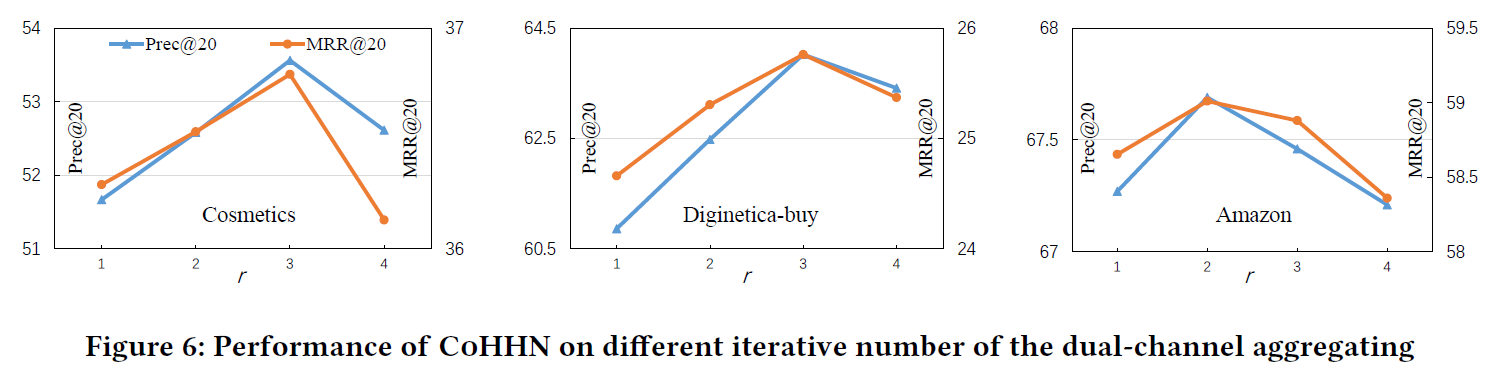
(1)2、3层性能最好,层数过多容易过平滑。
(2)Amazon 商品个数最少,所以达到最优性能需要的迭代次数最少。
结论
异质超图=异质图+超图:异质图——融合异质特征,超图——捕捉高阶依赖
双通道聚合:intra + inter ,聚合同类和异类信息,获得价格和兴趣偏好的初级表示
协同指导学习:捕捉价格偏好和兴趣偏好之间的复杂联系,获得语义增强的价格和兴趣偏好的表示
展望
融合更多特征,了例如品牌,卖家声誉等等。该模型可以适用于很多需要挖掘异质信息的任务。