Task02
Task02:精排模型 DeepFM DIN
推荐模型发展的时间线
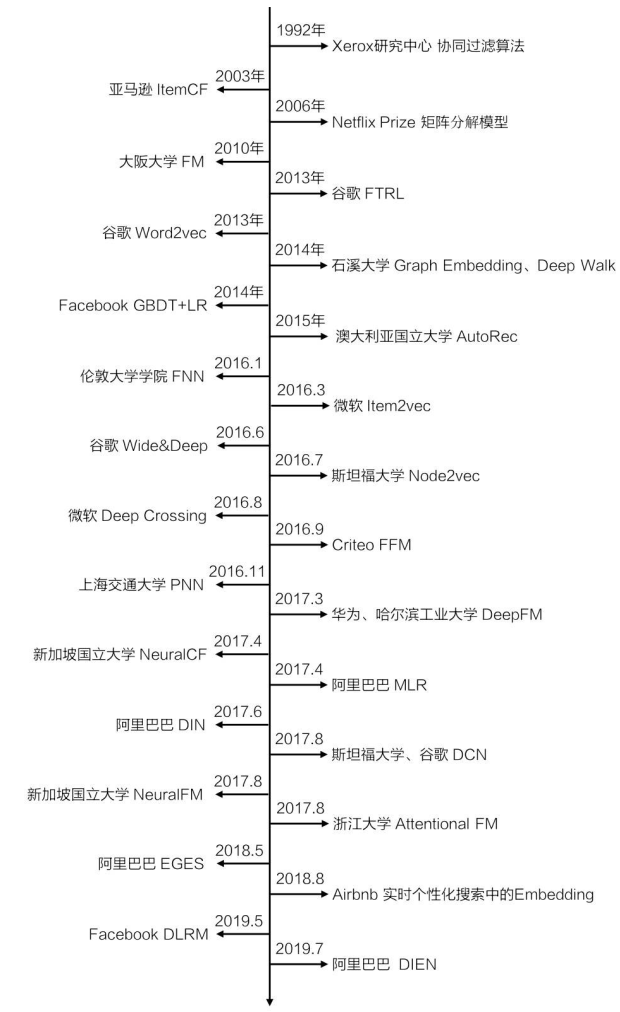
这张图来自[1],放出这张图的原因是便于从时间线上感受这些模型的发展。本期学习的 DIN 还算是比较独立的存在,它在前面模型 DNN 思想的基础上加入了注意力机制。而 DeepFM ,从时间线上可以看到 DeepFM 模型是在 FM、FNN、PNN、Wide&Deep 之后推出的,其实也是对这些模型的改进,为了更好地理解 DeepFM,至少得先了解它们。
DeepFM
DeepFM 提出的动机主要有两点:
CTR 预估任务中特征交叉至关重要,但是特征交叉通常需要非常专业的特征工程。例如Wide&Deep的Wide部分需要手工构造pairwise特征,huge size并且费人力,复杂。
一些模型例如FNN、PNN只能学习到高阶特征组合;Wide&Deep在输出层直接将低阶和高阶特征相加组合,很容易让模型最终偏向(bias)学习到低阶或者高阶的特征,而不能很好地结合。
针对上面两个问题,DeepFM的解决方案分别是:
- 改进 Wide&Deep 的 Wide 部分,使用 FM 代替手工构造特征
- Wide 部分和 Deep 部分使用相同的 embedding 输入,不会导致 bias
DeepFM 的前辈们
上面提到了FM、FNN、PNN、Wide&Deep,为了更好地理解 DeepFM ,这里简单介绍下:FM 捕捉低阶特征组合,FNN、PNN 捕捉高阶特征组合,Wide&Deep 的 Wide 部分捕捉低阶特征组合,Deep 部分捕捉高阶特征组合。更详细的介绍如下
低阶特征组合:FM
用[2]的例子介绍 FM ,假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。源数据如下:
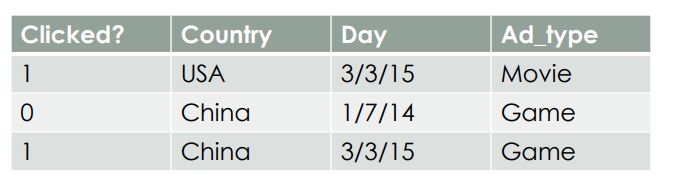
Clicked? 是 label ,Country、Day、Ad_type 是三类特征,并且都是类别型特征,需要经过 one-hot 编码才能转换为数值型特征,经过 one-hot 编码后如下所示:
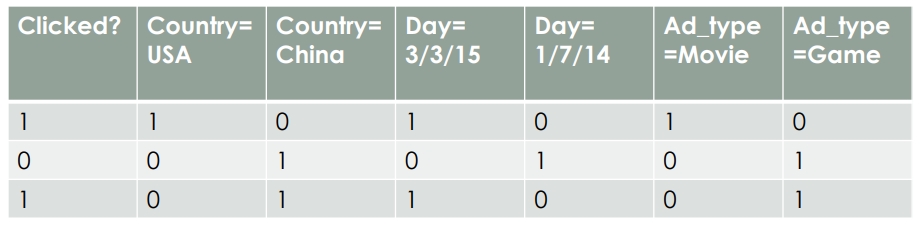
可以看出,经过 one-hot 编码,每条数据都变稀疏了,每个样本有7维特征,但仅有3维特征具有非零值。在实际场景中,商品种类、用户职业、地区等类别非常多,经过 one-hot 编码后样本维度会迅速上升,且非常稀疏。
POLY2
这时候其实可以用 LR 训练了,但是通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的,这也就是常说的特征交叉。因此,一个非常自然的想法诞生了,在 LR 的基础上加入二阶特征组合,这也是 POLY2 的思路:
公式中的 $x_i \in \{0,1\}$ 表示每个特征。
这样做考虑了二阶特征交叉,但是也产生了新的问题。
- 假设经过 one-hot 编码以后的样本特征维度为 $n$ ,那么上述公式中的 $w_{ij}$ 共有 $\frac{n(n-1)}{2}$ 个,权重参数量从 $O(n)$ 上升到了 $O(n^2)$ 。
- 并且 $w_{ij}$ 还有一个“训练难”的问题,因为每个参数 $w_{ij}$ 的训练需要大量 $x_i$ 和 $x_j$ 都非零的样本;由于样本数据本来就比较稀疏,满足“ $x_i$ 和 $x_j$ 都非零”的样本将会非常少。训练样本的不足,很容易导致参数 $w_{ij}$ 不准确,最终将严重影响模型的性能。
受矩阵分解算法的启发,FM 提出隐向量的概念,用两个向量的内积 $<\mathbf{w}_i,\mathbf{w}_j>$ 代替 $w_{ij}$ ,也就是每一维特征都对应一个隐向量,共有 $n$ 个隐向量,在做二阶特征交叉时,用两个向量的内积表示这两个组合特征的权重 $w_{ij}$,这样一来就解决了 POLY2 的两个问题:
- 权重参数量由 $O(n^2)$ 减少到 $O(nk),k<<n$ 。
- 隐向量的引入使得 $ x_{h} x_{i}$ 的参数和 $ x_{i} x_{j}$ 的参数不再是相互独立的,因此我们可以在样本稀疏的情况下相对合理地估计 FM 的二次项参数。具体来说, $ x_{h} x_{i}$ 和 $ x_{i} x_{j}$ 的系数分别为 $<\mathbf{w}_h,\mathbf{w}_i>$ 和$<\mathbf{w}_i,\mathbf{w}_j>$,它们之间有共同项 $\mathbf{w}_i$。也就是说,所有包含“ $x_i$ 的非零组合特征”(存在某个 $j\neq i$,使得 $ x_{i} x_{j}\neq 0$ )的样本都可以用来学习隐向量 $\mathbf{w}_i$,这很大程度上缓解了数据稀疏性的问题。相比POLY2, FM虽然丢失了某些具体特征组合的精确记忆能力, 但是泛化能力大大提高。
计算优化

补一个小知识点,FM的计算公式可以化简[4],将时间复杂度从 $O(n^2)$ 减少到 $O(n)$ 。
高阶特征组合:DNN、FNN
DNN
比起 FM 的二阶特征组合能力,DNN 能实现更高阶的特征组合。但是 DNN 也存在一些问题[3]:
当我们使用DNN网络解决推荐问题的时候,存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片:
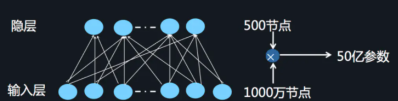
这样庞大的参数量也是不实际的。为了解决 DNN 参数量过大的局限性,可以采用非常经典的 Field 思想,将 OneHot 特征转换为 Dense Vector

此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
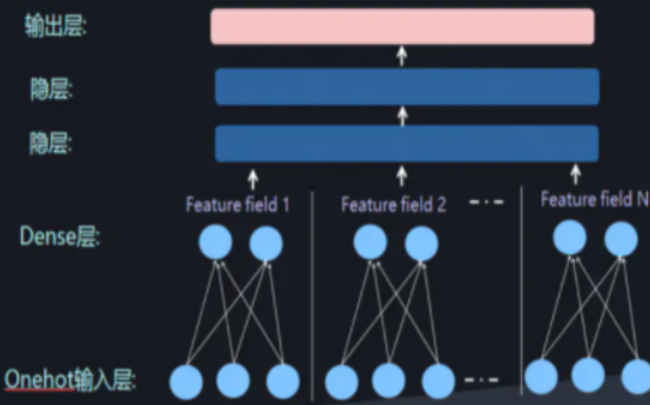
FNN
DNN 能够实现高阶特征组合,但是低阶的特征组合也很重要,于是一些模型例如 FNN ,在 DNN 基础上,增加 FM 来表示低阶的特征组合,以下是 FNN 的模型图。
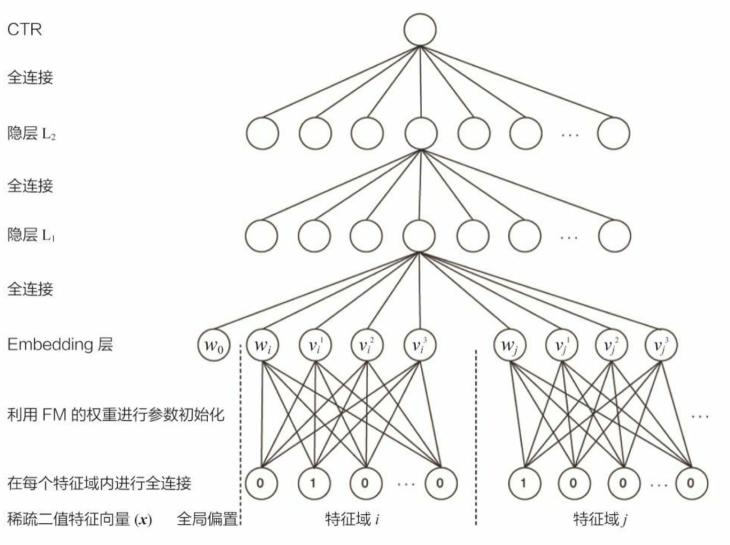
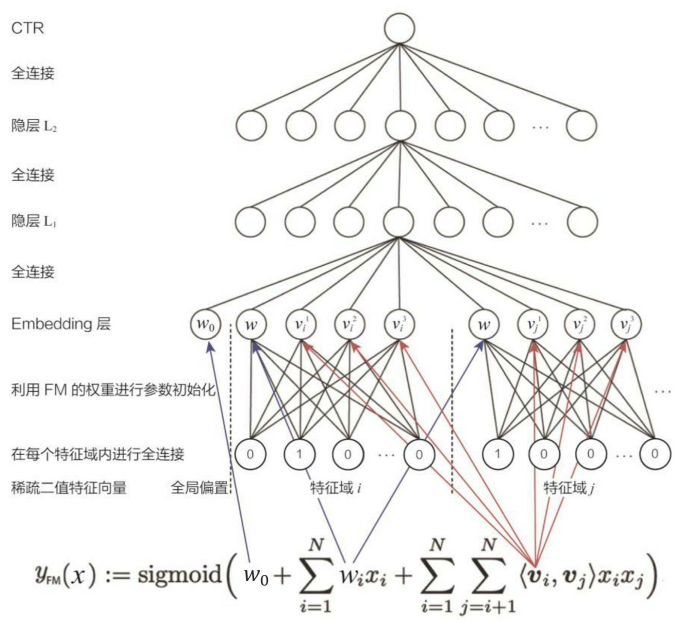
可以看出 FNN 在Embedding 层做了改进,利用 FM 的权重进行参数初始化,这样做其实有两点好处:
- 因为 1)Embedding 层的参数数量巨大;2)在进行梯度下降优化时,只有与非零特征相连的 Embedding 层权重会被更新。这两点原因导致 Embedding 层收敛速度很慢,利用 FM 训练好的隐向量初始化 Embedding 层的参数,相当于在初始化神经网络参数时,已经引入了有价值的先验信息。 也就是说, 神经网络训练的起点更接近目标最优点, 自然加速了整个神经网络的收敛过程。
- 模型图的 Embedding 层, $w_0$ 是 FM 公式里的偏置项,$w_1$ 是一阶特征组合项,剩下的是二阶特征组合项,所以 FNN 也加入了低阶特征组合(虽然经过 DNN 后这些低阶特征组合几乎没有了)
Wide&Deep
紧接着上面,“经过 DNN 后这些低阶特征组合几乎没有了”,这是实际上是由于 FNN 中,“ FM 预训练,再用 DNN 训练最终的模型”,这样串行的模式导致的,也就是虽然 FM 学到了低阶特征组合,但是 DNN 的全连接结构导致低阶特征在 DNN 中又被组合成了高阶特征组合,所以没有保留下低阶特征组合。看来我们已经找到问题了,将串行方式改进为并行方式能比较好的解决这个问题。于是Google提出了 Wide&Deep 模型,见下图。
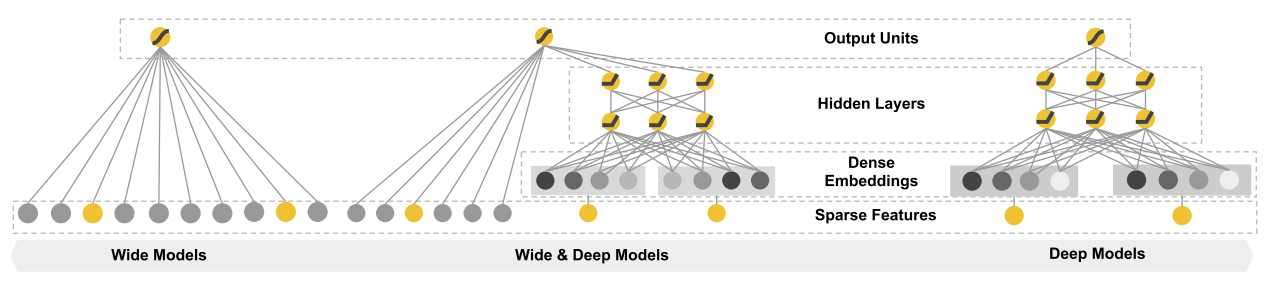
Wide&Deep 的设计初衷是为了赋予模型记忆能力和泛化能力,记忆能力通过 Wide 部分实现,泛化能力通过 Deep 部分实现。
“记忆能力” 可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。 一般来说, 协同过滤、 逻辑回归等简单模型有较强的“记忆能力”。 由于这类模型的结构简单, 原始数据往往可以直接影响推荐结果, 产生类似于“如果点击过A, 就推荐B”这类规则式的推荐, 这就相当于模型直接记住了历史数据的分布特点, 并利用这些记忆进行推荐。
“泛化能力” 可以被理解为模型传递特征的相关性, 以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。 矩阵分解比协同过滤的泛化能力强, 因为矩阵分解引入了隐向量这样的结构, 使得数据稀少的用户或者物品也能生成隐向量, 从而获得有数据支撑的推荐得分, 这就是非常典型的将全局数据传递到稀疏物品上, 从而提高泛化能力的例子。 再比如, 深度神经网络通过特征的多次自动组合, 可以深度发掘数据中潜在的模式, 即使是非常稀疏的特征向量输入, 也能得到较稳定平滑的推荐概率, 这就是简单模型所缺乏的“泛化能力”。
但是如果深入探究 Wide&Deep 的构成方式,虽然将整个模型的结构调整为了并行结构,在实际的使用中 Wide 部分需要较为精巧的特征工程,换句话说人工处理对于模型的效果具有比较大的影响,大家可以看到下图红圈内的 Wide 部分采用了两个 id 类特征的乘积,这是 Google 团队根据业务精心选择的想让模型直接记忆的特征组合。
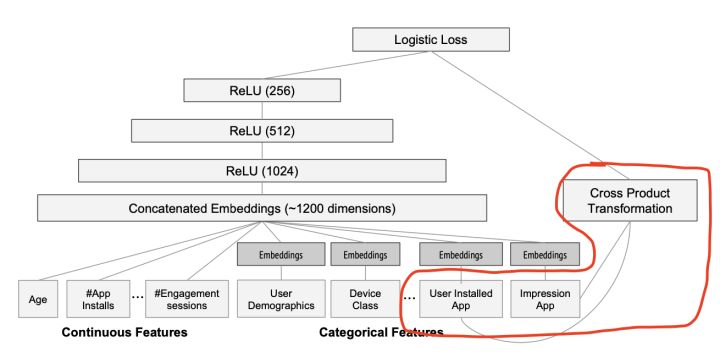
Wide&Deep 其实还有一个没那么容易能够发现的问题,我们看下面这张图(图片来自FunRec):
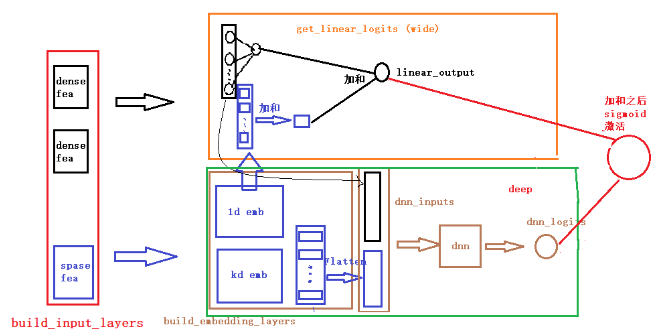
在模型前向计算的时候,Wide 和 Deep 部分的输入不同,Wide 的输入只有低阶特征组合,Deep 则可以输入低阶和高阶;两部分各自输出一个标量 logits,最后学习它们的权重系数加权求和,再过 sigmoid 激活。DeepFM 的论文里,指出这样做可能使得模型最终偏向学习到低阶或者高阶的特征,不能做到很好的结合,究其原因还是高阶和低阶特征的输入是分开的。
回到DeepFM
综合上述几个模型,FM 能够高效进行特征交叉捕捉低阶特征组合;DNN、FNN、PNN 能够捕捉高阶特征组合;Wide&Deep 结合两者,同时捕捉低阶和高阶特征,但仍有两个问题:1)学习有偏,最后会偏向学习低阶或者高阶特征。2)Wide 部分需要手工设计特征,费时费力。
至此,终于轮到 DeepFM 登场。
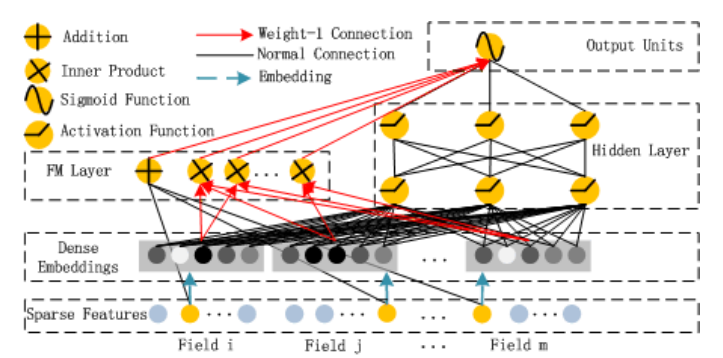
DeepFM 仍然沿用了 Wide&Deep “记忆+泛化”两部分建模的思想,设计 FM Component 负责“记忆”,Deep Component 负责“泛化”。其中巧妙地利用 FM 的思想解决了 Wide&Deep 的两个问题:特征工程困难和学习有偏。
具体是如何用 FM 思想解决这两部分问题的呢?下面看 FM 部分的模型图:
FM Component
FM 部分,改进 Wide&Deep 的 Wide,使得不再需要手动构造(二阶)交叉特征,也能捕捉低阶特征组合。

公式:
这里每个 field 都是 one-hot ,原文里说的,所以不用纠结同一个 field 里是否是 multi-hot 了,如果是 multi-hot 也可以用各种 pooling 方式转化成一个向量。
在 FM Layer,共有两种操作,Addition 和 Inner Product(分别用绿色和蓝色箭头标出)。
- Addition. 对 Sparse Feature(Field level)线性加和,即 $\langle w, x\rangle$ .
- Inner Product. 将每个 field 的 one-hot 向量转化成 dense embedding,把它看作 FM 的 latent vector(Dense Embeddings 层在 Deep Component 里介绍),然后做点积操作即 $\sum_{i=1}^{d} \sum_{j=i+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{i} \cdot x_{j}$ .
这里我曾经纠结了很久,因为不知道特征究竟是如何组合的,是 $\frac{n(n-1)}{2}$ 次组合,还是 $\frac{m(m-1)}{2}$ 次组合。最后查阅资料加上自己整理,回答是这样的:
- $\sum_{i=1}^{d} \sum_{j=i+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{i} \cdot x_{j}$ 反映二阶特征交叉,$V_i$ , $V_j$ 是特征对应的 latent vector,也就是对应的embedding。
所以这里其实不是所有 feature(所有field里的所有feature,num=$n$)的两两交叉,其实是 $m$ 个域的特征交叉,不过每个域是可以涵盖到域里所有的 feature 的(每个域从域包含的特征里选择一个,因为是 one-hot)。也就是说,当一条数据输入进去的时候,不会对所有 feature 做特征交叉(即 $\frac{n(n-1)}{2}$ 次组合),而是会对所有域做特征交叉(即 $\frac{m(m-1)}{2}$ 次组合),但是当数据量足够多时,就能涵盖到所有feature的交叉。
Deep Component
Deep 部分和 DNN 一样,捕捉高阶特征组合。
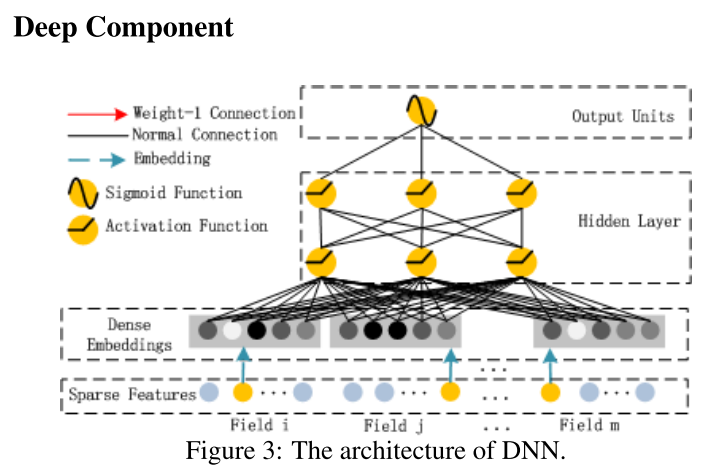
用全连接的方式将 Dense Embedding 输入到 Hidden Layer ,这里面 Dense Embeddings 就是用 Field 思想解决 DNN 中的参数爆炸问题,这也是推荐模型中常用的处理方法。然后 Dense Embeddings 拼接以后传入 DNN 。
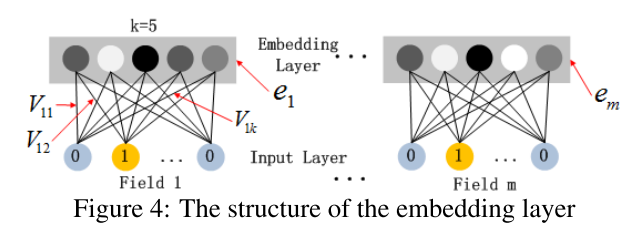
上图是 Dense Embeddings 层的结构,这里有两点需要指出:1)尽管不同 field 的长度可能不同,但 embedding 维度 $k$ 都是相同的;2)FM 里的 latent vector 现在充当作为网络的权重参数(回忆一下矩阵乘法,有 1 的地方对应的一列权重参数就是 latent vector),它们是学习得到的,被用来将 field 的 one-hot 向量压缩成 embedding 向量。
与 FNN 不同的是,这里的 latent vector 不是预训练而是随机初始化得到的,并且是不断学习优化的。

至此我们还可以发现,FM 部分和 Deep 部分是共享 embedding 的,这就解决了“学习有偏”的问题,因为高阶和低阶特征都是从同一个 embedding 层获得的。再回想 FM 部分,用 latent vector 做内积组合二阶特征的方式避免了“特征工程困难”的问题。DeepFM 的主要贡献就是在于对 Wide&Deep 进行了这两方面的改进。
DeepFM 代码
开源代码见:torch-rechub/DeepFM.ipynb at main · datawhalechina/torch-rechub (github.com)
数据集
使用的是 Criteo 的一个 sample

特征工程

至此都比较好理解。
Dense 特征
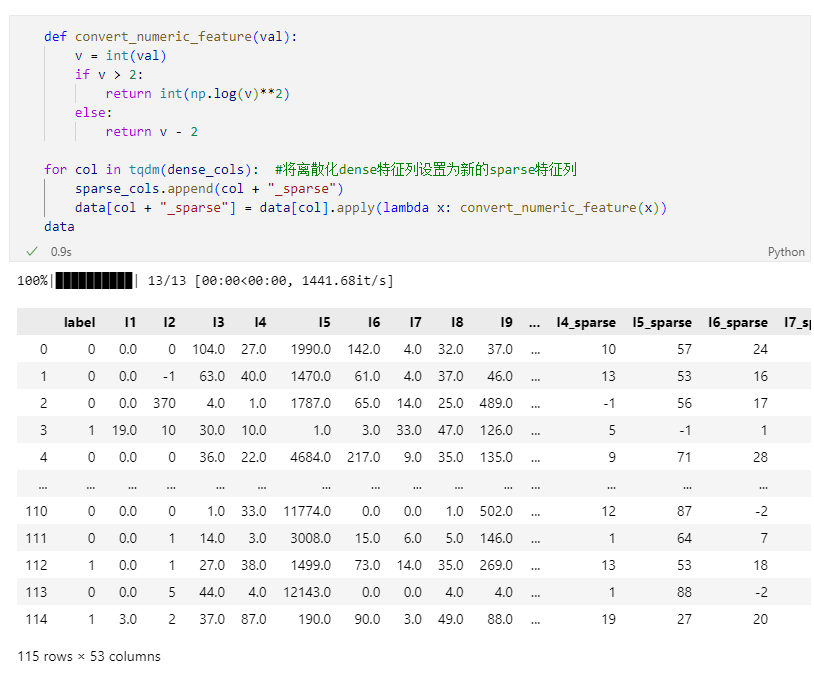
这里 convert_numeric_feature() 有点令人费解,据说是比赛中冠军队伍使用的方法,emm,EDA做得好,同时不得不佩服大佬们的创造力~ 总之经过这样的变换,将 dense 特征都转化成了新的 sparse 特征列。

将 dense 特征转化成新的 sparse 特征后,dense 特征本身还要做一些归一化操作,这里使用 MinMaxScaler() 。
其实 Wide&Deep 里做完归一化以后还做了分组,见下图:

Sparse 特征

直接用 LabelEncoder() 编码。
定义 DataGenerator (Dataset + Dataloader)
1 | #重点:将每个特征定义为torch-rechub所支持的特征基类,dense特征只需指定特征名,sparse特征需指定特征名、特征取值个数(vocab_size)、embedding维度(embed_dim) |
定义 Model
1 | from torch_rechub.models.ranking import DeepFM |
我们进入 DeepFM 模型内部看一看:
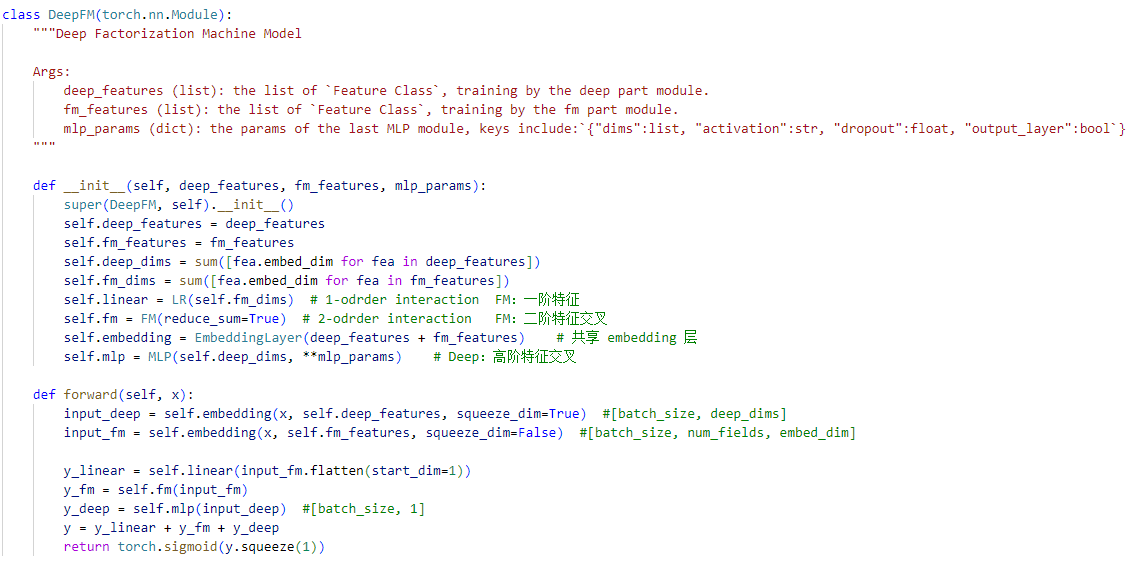
从 forward() 里可以看出,在代码实现时,其实不完全是分成 deep 和 fm 两部分,而是分成 deep 、fm、linear 三部分。论文里的 fm 部分是包含一阶特征和二阶特征交叉的,代码实现的时候把一阶特征单独拿出来用 linear 实现。
LR 的实现如下:

FM 的实现如下(不是完全体的 FM ,这里是只计算二阶特征的 FM ):
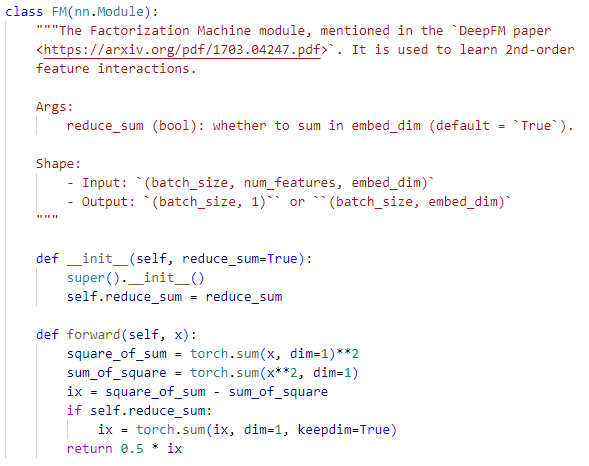
这里 FM 的公式是计算优化后的,可以参考下面的公式:
MLP 的实现如下:

我们在传参的时候:
1 | mlp_params={"dims": [256, 128], "dropout": 0.2, "activation": "relu"}, |
这里的 dims 的参数列表就表示从输入到输出,维度依次是多少,这个例子中就是: input_dim —> 256 —> 128 —> 1 。没有指定 “output_layer” 的话,会默认再过一个 nn.linear() 让维度变成 1 ,当然 output_layer 后是不接激活函数的。
另外注意这里添加了 BatchNorm 。
定义 trainer
1 | # 模型训练,需要学习率、设备等一般的参数,此外我们还支持earlystoping策略,及时发现过拟合 |
不需要定义损失函数,因为 ctr 预估任务都是 BCE loss,默认评价指标是 auc 。
训练和评估
1 | ctr_trainer.fit(train_dataloader, val_dataloader) |
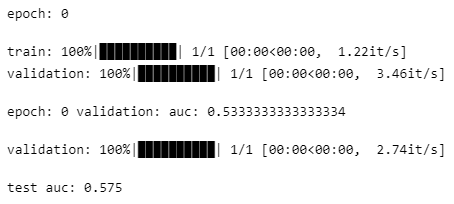
使用其它排序模型
调用现成模型
调用现成的模型非常容易,只需要修改 model 参数:
1 | #定义相应的模型,用同样的方式训练 |
DIN
DIN 还算是比较独立的存在,它在前面模型 DNN 思想的基础上加入了注意力机制。
Base Model
DIN 也是广告推荐场景,一般来说,模型的输入特征自然分为三部分:一部分是用户 $u$ 的特征(下图的 User Profile 和 User Behaviors),一部分是候选广告 $a$ 的特征(Candidate Ad),一部分是上下文特征(Context Features)。我们把用户的 User Behaviors 和广告的 Candidate Ad 两类特征组单独拿出来看,为什么要单独挑出来?因为它们都含有两个非常重要的特征——商品 id 和商铺 id。用户特征里的商品 id 是一个序列,代表用户曾经点击过的商品集合,商铺 id 统里;而广告特征里的商品 id 和商铺 id 就是广告对应的商品 id 和商铺 id 。下图是论文中用到的一个 base model,也是 DIN 之前绝大多数模型的做法,即给模型输入 one-hot 或 multi-hot 向量,再经过 Embedding 层转化成 $1 \times d$ 的 dense embedding 向量,multi-hot 向量还得在特征组(Field)内进行 pooling 操作转化才能转化成 $1 \times d$ 的向量,论文选用最常用的 sum pooling。在得到每个特征组的向量后,对所有向量进行 concat 然后送入 DNN ,这就是最一般的做法。
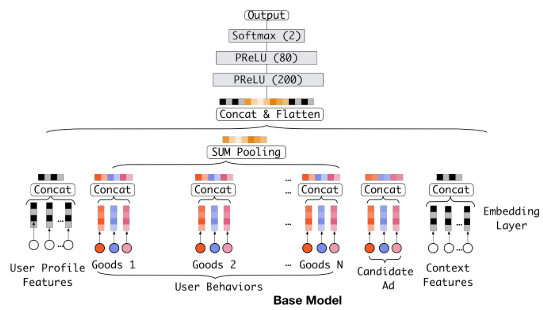
这些模型在这种个性化广告点击预测任务中存在的问题就是无法表达用户广泛的兴趣,因为这些模型在得到各个特征的embedding之后,就蛮力拼接了,然后就各种交叉等。这时候根本没有考虑之前用户历史行为商品具体是什么,究竟用户历史行为中的哪个会对当前的点击预测带来积极的作用。 而实际上,对于用户点不点击当前的商品广告,很大程度上是依赖于他的历史行为的,王喆老师[1]举了个例子
假设广告中的商品是键盘, 如果用户历史点击的商品中有化妆品, 包包,衣服, 洗面奶等商品, 那么大概率上该用户可能是对键盘不感兴趣的, 而如果用户历史行为中的商品有鼠标, 电脑,iPad,手机等, 那么大概率该用户对键盘是感兴趣的, 而如果用户历史商品中有鼠标, 化妆品, T-shirt和洗面奶, 鼠标这个商品embedding对预测“键盘”广告的点击率的重要程度应该大于后面的那三个。
这里也就是说如果是之前的那些深度学习模型,是没法很好的去表达出用户这广泛多样的兴趣的,如果想表达的准确些, 那么就得加大隐向量的维度,让每个特征的信息更加丰富, 那这样带来的问题就是计算量上去了,毕竟真实情景尤其是电商广告推荐的场景,特征维度的规模是非常大的。 并且根据上面的例子, 也并不是用户所有的历史行为特征都会对某个商品广告点击预测起到作用。所以对于当前某个商品广告的点击预测任务,没必要考虑之前所有的用户历史行为。
Motivation
这样, DIN的动机就出来了,在业务的角度,我们应该自适应的去捕捉用户的兴趣变化,这样才能较为准确的实施广告推荐;而放到模型的角度, 我们应该考虑到用户的历史行为商品与当前商品广告的一个关联性,如果用户历史商品中很多与当前商品关联,那么说明该商品可能符合用户的品味,就把该广告推荐给他。而一谈到关联性的话, 我们就容易想到“注意力”的思想了, 所以为了更好的从用户的历史行为中学习到与当前商品广告的关联性,学习到用户的兴趣变化, 作者把注意力引入到了模型,设计了一个”local activation unit”结构,利用候选商品和历史问题商品之间的相关性计算出权重,这个就代表了对于当前商品广告的预测,用户历史行为的各个商品的重要程度大小, 而加入了注意力权重的深度学习网络,就是这次的主角DIN, 下面具体来看下该模型。
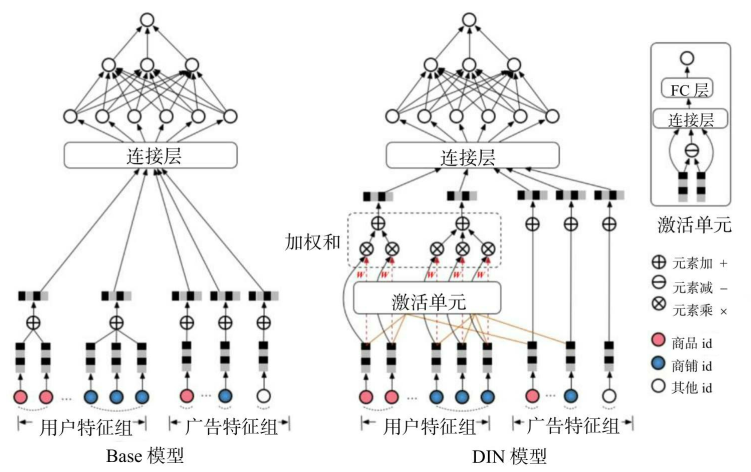
论文原版图:

王喆老师的配图:
注意力激活单元
注意力机制的公式可以定义如下:
其中, $\boldsymbol{V}_{\mathrm{u}}$ 是用户的Embedding向量, $\boldsymbol{V}_{\mathrm{a}}$ 是候选广告商品的 Embedding 向量, $\boldsymbol{V}_{\mathrm{i}}$ 是用户 $u$ 的第 $i$ 次行为的 Embedding 向量。 这里用户的行为就是浏览商品或店铺, 因此行为的 Embedding 向量就是那次浏览的商品或店铺的 Embedding 向量。
因为加入了注意力机制, 所以 $\boldsymbol{V}_{\mathrm{u}}$ 从过去 $\boldsymbol{V}_{\mathrm{i}}$ 的加和变成了 $\boldsymbol{V}_{\mathrm{i}}$ 的加权和, $\boldsymbol{V}_{\mathrm{i}}$ 的权重 $w_i$ 就由 $\boldsymbol{V}_{\mathrm{i}}$ 与 $\boldsymbol{V}_{\mathrm{a}}$ 的关系决定, 也就是公式中的$ g\left(\boldsymbol{V}_{i}, \boldsymbol{V}_{\mathrm{a}}\right)$, 即“注意力得分”。
那么到底应该如何计算注意力得分呢,论文设计了“local activation unit”,即注意力激活单元。这个注意力激活单元本质上也是小的神经网络,看王喆老师的配图比较清晰,在图的右上角。
可以看出, 激活单元的输入层是两个 Embedding 向量, 经过元素减(element-wise minus) 操作后, 与原Embedding向量一同连接后形成全连接层的输入, 最后通过单神经元输出层生成注意力得分。
注意商铺 id 只跟用户历史行为中的商铺 id 序列发生作用, 商品 id 只跟用户的商品 id 序列发生作用, 因为注意力的轻重更应该由同类信息的相关性决定。
有意思的发现
论文作者发现用 LSTM 建模用户的历史行为,效果没有提升。作者提出,可能原因是会引入噪声。挺有意思哈哈哈哈,因为后面几年序列推荐火起来了,专门研究用户历史行为!这里作者说后续研究是不是 DIEN,还没看过论文,还不知道。

DIN代码
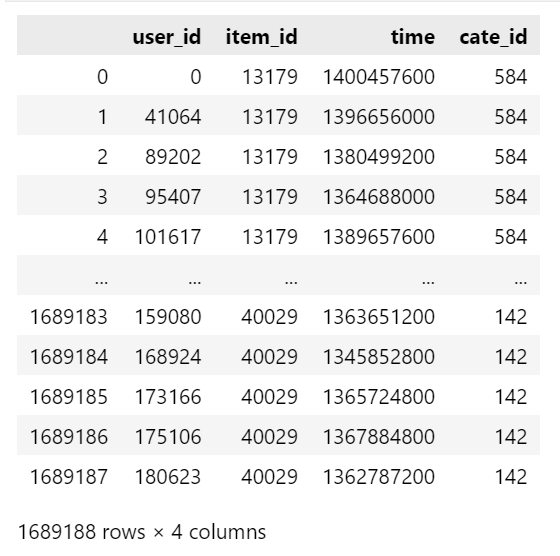
这里我们以Amazon-Electronics为例,原数据是json格式,我们提取所需要的信息预处理为一个仅包含user_id, item_id, cate_id, time四个特征列的CSV文件。
数据预处理
完整的数据长这样,共有 1,689,188 条用户交互记录。
在该数据集上,我们没有 dense feature,只有 sparse feature,除此之外我们还要构造 sequence feature。

这里用一个关键函数 create_seq_features() 构造序列特征,我们进到函数内看一看,解析见注释。
1 | def create_seq_features(data, seq_feature_col=['item_id', 'cate_id'], max_len=50, drop_short=3, shuffle=True): |
构建完序列特征后:
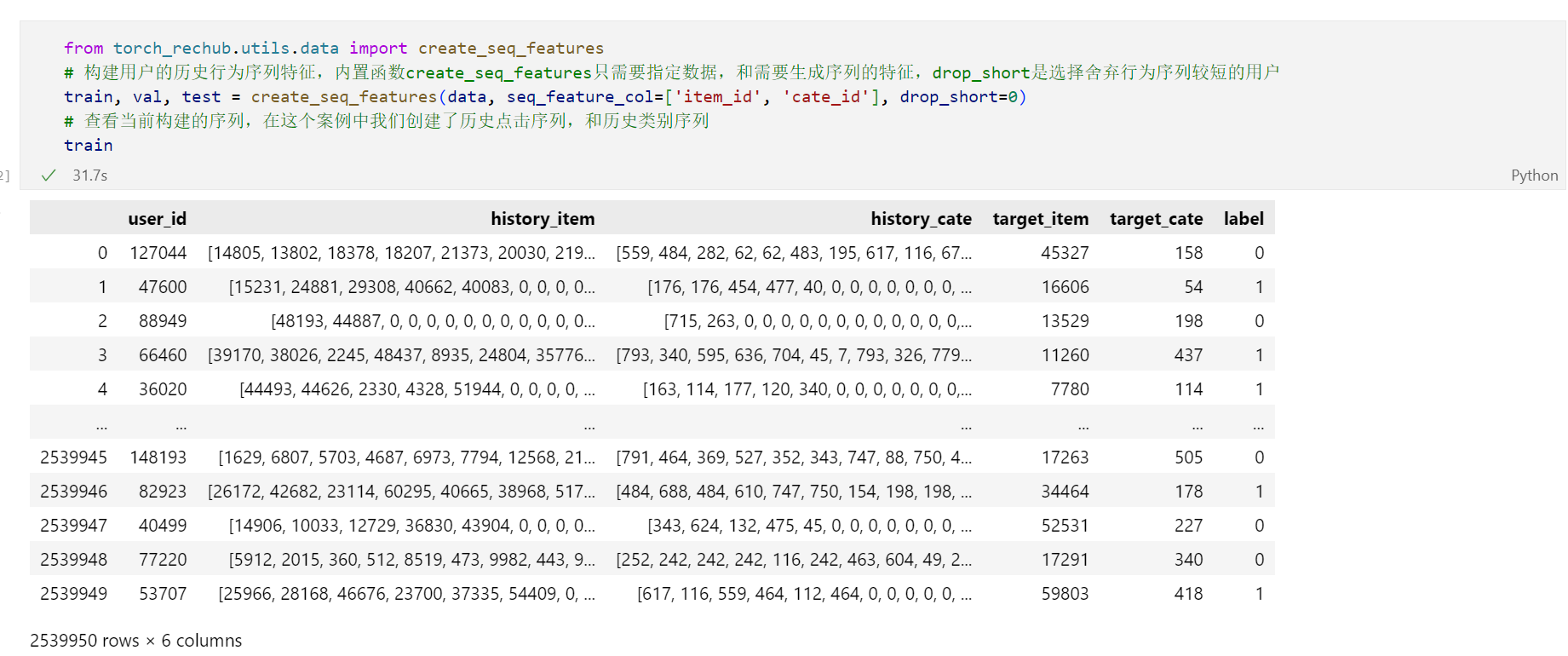
让模型明白如何处理每一类特征
在DIN模型中,我们讲使用了两种类别的特征,分别是类别特征和序列特征。对于类别特征,我们希望模型将其输入Embedding层,而对于序列特征,我们不仅希望模型将其输入Embedding层,还需要计算target-attention分数,所以需要指定DataFrame中每一列的含义,让模型能够正确处理。
在这个案例中,因为我们使用user_id,item_id和item_cate这三个类别特征,使用用户的item_id和cate的历史序列作为序列特征。在torch-rechub我们只需要调用DenseFeature, SparseFeature, SequenceFeature这三个类,就能自动正确处理每一类特征。
1 | from torch_rechub.basic.features import DenseFeature, SparseFeature, SequenceFeature |
上面 + 2 的原因是:这里建立 embedding 蹭,需要按照特征表大小建立查表,用 max 获得被 labelEncoder 后的最大值, +的第一个 1 是因为把 0 作为 mask 了,+的第二个 1 是空出来以为冗余,这是编程呢个的习惯,也可以不加。
定义数据集
在上述步骤中,我们制定了每一列的数据如何处理、数据维度、embed后的维度,目的就是在构建模型中,让模型知道每一层的参数。接下来我们生成训练数据,用于训练,一般情况下,我们只需要定义一个字典装入每一列特征即可。
1 | from torch_rechub.utils.data import df_to_dict, DataGenerator |
定义 DataGenerator (Dataset + Dataloader)
1 | # 构建dataloader,指定模型读取数据的方式,和区分验证集测试集、指定batch大小 |
定义模型
1 | from torch_rechub.models.ranking import DIN |
我们进入 DIN 模型看一看~
定义训练器
1 | from torch_rechub.trainers import CTRTrainer |
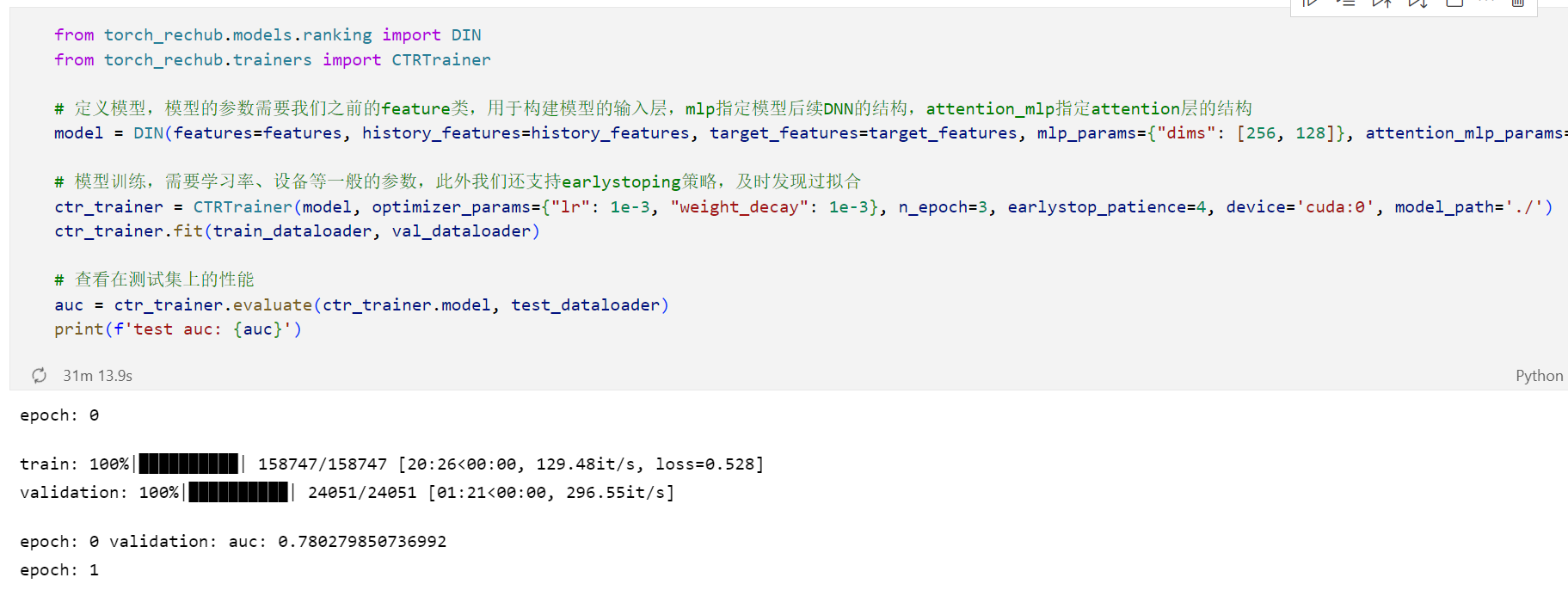
训练和评估
1 | # 模型训练 |
训练比较慢,只跑了一个 epoch:
总结
以 DeepFM 为切入点,学习了 FM、POLY2、FNN、PNN、Wide&Deep 以及 DeepFM 模型,对这几个模型的发展脉络有了比较清晰的认识。用 Torch-RecHub 实现 DeepFM 也非常容易。DIN 是本次学习中学习的第一个序列模型,只做了 target-attention,放在现在来看 DIN 还处于序列建模比较萌芽的阶段。
Task2,以两个精排模型为线索,学到了很多!期待下一节的召回模型。
虽然忙面试,也要坚持打卡!
参考资料
[1]《深度学习推荐系统》王喆
[2] FM (cmu.edu)
[3] https://datawhalechina.github.io/fun-rec/#/ch02/ch2.2/ch2.2.3/DeepFM